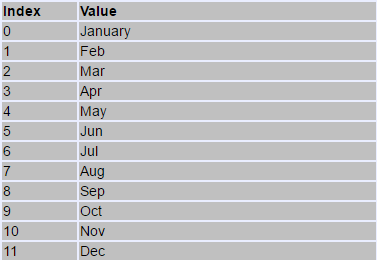
C++
1 - C++ OVERVIEW
Compilers
The essential tools needed to follow these tutorials are a computer and a compiler toolchain able to compile C++ code and build the programs to run on it.
C++ is a language that has evolved much over the years, and these tutorials explain many features added recently to the language. Therefore, in order to properly follow the tutorials, a recent compiler is needed. It shall support (even if only partially) the features introduced by the 2011 standard.
Many compiler vendors support the new features at different degrees. See the bottom of this page for some compilers that are known to support the features needed. Some of them are free!
If for some reason, you need to use some older compiler, you can access an older version of these tutorials here (no longer updated).
What is a compiler?
Computers understand only one language and that language consists of sets of instructions made of ones and zeros. This computer language is appropriately called machine language.
A single instruction to a computer could look like this:
| 00000 | 10011110 |
A particular computer's machine language program that allows a user to input two numbers, adds the two numbers together, and displays the total could include these machine code instructions:
| 00000 | 10011110 |
| 00001 | 11110100 |
| 00010 | 10011110 |
| 00011 | 11010100 |
| 00100 | 10111111 |
| 00101 | 00000000 |
As you can imagine, programming a computer directly in machine language using only ones and zeros is very tedious and error prone. To make programming easier, high level languages have been developed. High level programs also make it easier for programmers to inspect and understand each other's programs easier.
This is a portion of code written in C++ that accomplishes the exact same purpose:
Even if you cannot really understand the code above, you should be able to appreciate how much easier it will be to program in the C++ language as opposed to machine language.
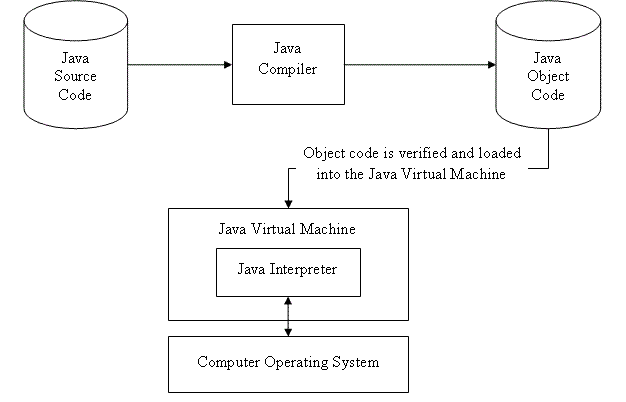
Because a computer can only understand machine language and humans wish to write in high level languages high level languages have to be re-written (translated) into machine language at some point. This is done by special programs called compilers, interpreters, or assemblers that are built into the various programming applications.
C++ is designed to be a compiled language, meaning that it is generally translated into machine language that can be understood directly by the system, making the generated program highly efficient. For that, a set of tools are needed, known as the development toolchain, whose core are a compiler and its linker.
Console programs
Console programs are programs that use text to communicate with the user and the environment, such as printing text to the screen or reading input from a keyboard.
Console programs are easy to interact with, and generally have a predictable behavior that is identical across all platforms. They are also simple to implement and thus are very useful to learn the basics of a programming language: The examples in these tutorials are all console programs.
The way to compile console programs depends on the particular tool you are using.
The easiest way for beginners to compile C++ programs is by using an Integrated Development Environment (IDE). An IDE generally integrates several development tools, including a text editor and tools to compile programs directly from it.
Here you have instructions on how to compile and run console programs using different free Integrated Development Interfaces (IDEs):
| IDE | Platform | Console programs |
|---|---|---|
| Code::blocks | Windows/ Linux/ MacOS | Compile console programs using Code::blocks |
| Visual Studio Express | Windows | Compile console programs using VS Express 2013 |
| Dev-C++ | Windows | Compile console programs using Dev-C++ |
If you happen to have a Linux or Mac environment with development features, you should be able to compile any of the examples directly from a terminal just by including C++11 flags in the command for the compiler:
| Compiler | Platform | Command |
|---|---|---|
| GCC | Linux, among others... | g++ -std=c++0x example.cpp -o example_program |
| Clang | OS X, among others... | clang++ -std=c++11 -stdlib=libc++ example.cpp -o example_program |
2 - C++ STRUCTURE OF A PROGRAM
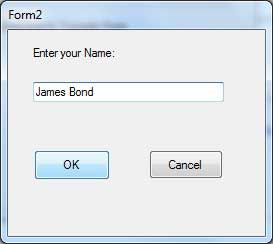
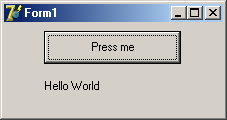
The best way to learn a programming language is by writing programs. Typically, the first program beginners write is a program called "Hello World", which simply prints "Hello World" to your computer screen. Although it is very simple, it contains all the fundamental components C++ programs have:
Hello World!
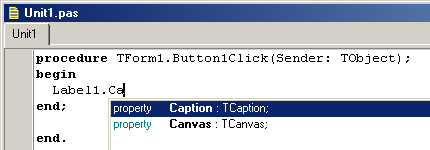
The left panel above shows the C++ code for this program. The right panel shows the result when the program is executed by a computer. The grey numbers to the left of the panels are line numbers to make discussing programs and researching errors easier. They are not part of the program.
Let's examine this program line by line:
Line 1: // my first program in C++
Two slash signs indicate that the rest of the line is a comment inserted by the programmer but which has no effect on the behavior of the program. Programmers use them to include short explanations or observations concerning the code or program. In this case, it is a brief introductory description of the program.
Line 2: #include <iostream>
Lines beginning with a hash sign (#) are directives read and interpreted by what is known as the preprocessor. They are special lines interpreted before the compilation of the program itself begins. In this case, the directive #include <iostream>, instructs the preprocessor to include a section of standard C++ code, known as header iostream, that allows to perform standard input and output operations, such as writing the output of this program (Hello World) to the screen.
Line 3: A blank line.
Blank lines have no effect on a program. They simply improve readability of the code.
Line 4: int main ()
This line initiates the declaration of a function. Essentially, a function is a group of code statements which are given a name: in this case, this gives the name "main" to the group of code statements that follow. Functions will be discussed in detail in a later chapter, but essentially, their definition is introduced with a succession of a type (int), a name (main) and a pair of parentheses (()), optionally including parameters.
The function named main is a special function in all C++ programs; it is the function called when the program is run. The execution of all C++ programs begins with the main function, regardless of where the function is actually located within the code.
Lines 5 and 7: { and }
The open brace ({) at line 5 indicates the beginning of main's function definition, and the closing brace (}) at line 7, indicates its end. Everything between these braces is the function's body that defines what happens when main is called. All functions use braces to indicate the beginning and end of their definitions.
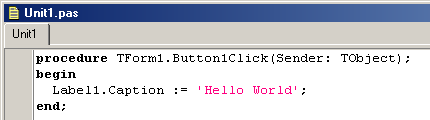
Line 6: std::cout< "Hello World!";
This line is a C++ statement. A statement is an expression that can actually produce some effect. It is the meat of a program, specifying its actual behavior. Statements are executed in the same order that they appear within a function's body.
This statement has three parts: First, std::cout, which identifies the standard character output device (usually, this is the computer screen). Second, the insertion operator (<<), which indicates that what follows is inserted into std::cout. Finally, a sentence within quotes ("Hello world!"), is the content inserted into the standard output.
Notice that the statement ends with a semicolon (;). This character marks the end of the statement, just as the period ends a sentence in English. All C++ statements must end with a semicolon character. One of the most common syntax errors in C++ is forgetting to end a statement with a semicolon.
You may have noticed that not all the lines of this program perform actions when the code is executed. There is a line containing a comment (beginning with //). There is a line with a directive for the preprocessor (beginning with #). There is a line that defines a function (in this case, the main function). And, finally, a line with a statements ending with a semicolon (the insertion into cout), which was within the block delimited by the braces ( { } ) of the main function.
The program has been structured in different lines and properly indented, in order to make it easier to understand for the humans reading it. But C++ does not have strict rules on indentation or on how to split instructions in different lines.
For example, instead of
We could have written:
all in a single line, and this would have had exactly the same meaning as the preceding code.
In C++, the separation between statements is specified with an ending semicolon (;), with the separation into different lines not mattering at all for this purpose. Many statements can be written in a single line, or each statement can be in its own line. The division of code in different lines serves only to make it more legible and schematic for the humans that may read it, but has no effect on the actual behavior of the program.
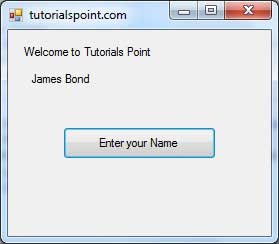
Now, let's add an additional statement to our first program:
Hello World! I'm a C++ program
In this case, the program performed two insertions into std::cout in two different statements. Once again, the separation in different lines of code simply gives greater readability to the program, since main could have been perfectly valid defined in this way:
The source code could have also been divided into more code lines instead:
And the result would again have been exactly the same as in the previous examples.
Preprocessor directives (those that begin by #) are out of this general rule since they are not statements. They are lines read and processed by the preprocessor before proper compilation begins. Preprocessor directives must be specified in their own line and, because they are not statements, do not have to end with a semicolon (;).
Comments
As noted above, comments do not affect the operation of the program; however, they provide an important tool to document directly within the source code what the program does and how it operates.
C++ supports two ways of commenting code:
The first of them, known as line comment, discards everything from where the pair of slash signs (//) are found up to the end of that same line. The second one, known as block comment, discards everything between the /* characters and the first appearance of the */ characters, with the possibility of including multiple lines.
Let's add comments to our second program:
Hello World! I'm a C++ program
If comments are included within the source code of a program without using the comment characters combinations //, /* or */, the compiler takes them as if they were C++ expressions, most likely causing the compilation to fail with one, or several, error messages.
Using namespace std
If you have seen C++ code before, you may have seen cout being used instead of std::cout. Both name the same object: the first one uses its unqualified name (cout), while the second qualifies it directly within the namespace std (as std::cout).
cout is part of the standard library, and all the elements in the standard C++ library are declared within what is a called a namespace: the namespace std.
In order to refer to the elements in the std namespace a program shall either qualify each and every use of elements of the library (as we have done by prefixing cout with std::), or introduce visibility of its components. The most typical way to introduce visibility of these components is by means of using declarations:
using namespace std;
The above declaration allows all elements in the std namespace to be accessed in an unqualified manner (without the std:: prefix).
With this in mind, the last example can be rewritten to make unqualified uses of cout as:
Hello World! I'm a C++ program
Both ways of accessing the elements of the std namespace (explicit qualification and using declarations) are valid in C++ and produce the exact same behavior. For simplicity, and to improve readability, the examples in these tutorials will more often use this latter approach with using declarations, although note that explicit qualification is the only way to guarantee that name collisions never happen.
3 - C++ VARIABLES AND TYPES
The usefulness of the "Hello World" programs shown in the previous chapter is rather questionable. We had to write several lines of code, compile them, and then execute the resulting program, just to obtain the result of a simple sentence written on the screen. It certainly would have been much faster to type the output sentence ourselves.
However, programming is not limited only to printing simple texts on the screen. In order to go a little further on and to become able to write programs that perform useful tasks that really save us work, we need to introduce the concept of variables.
Let's imagine that I ask you to remember the number 5, and then I ask you to also memorize the number 2 at the same time. You have just stored two different values in your memory (5 and 2). Now, if I ask you to add 1 to the first number I said, you should be retaining the numbers 6 (that is 5+1) and 2 in your memory. Then we could, for example, subtract these values and obtain 4 as result.
The whole process described above is a simile of what a computer can do with two variables. The same process can be expressed in C++ with the following set of statements:
Obviously, this is a very simple example, since we have only used two small integer values, but consider that your computer can store millions of numbers like these at the same time and conduct sophisticated mathematical operations with them.
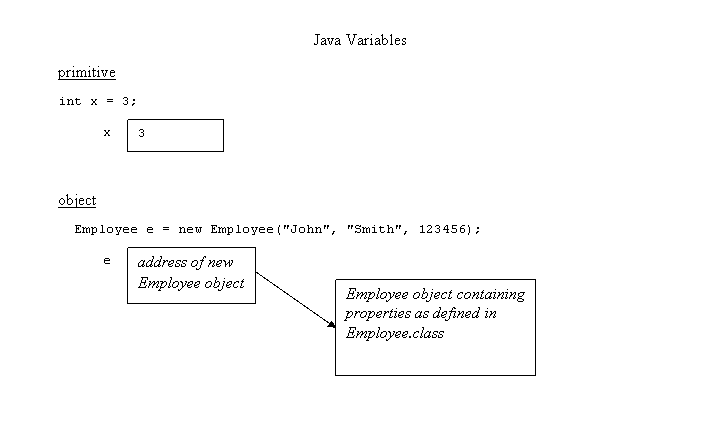
We can now define variable as a portion of memory to store a value.
Each variable needs a name that identifies it and distinguishes it from the others. For example, in the previous code the variable names were a, b, and result, but we could have called the variables any names we could have come up with, as long as they were valid C++ identifiers.
Identifiers
A valid identifier is a sequence of one or more letters, digits, or underscore characters (_). Spaces, punctuation marks, and symbols cannot be part of an identifier. In addition, identifiers shall always begin with a letter. They can also begin with an underline character (_), but such identifiers are -on most cases- considered reserved for compiler-specific keywords or external identifiers, as well as identifiers containing two successive underscore characters anywhere. In no case can they begin with a digit.
C++ uses a number of keywords to identify operations and data descriptions; therefore, identifiers created by a programmer cannot match these keywords. The standard reserved keywords that cannot be used for programmer created identifiers are:
alignas, alignof, and, and_eq, asm, auto, bitand, bitor, bool, break, case, catch, char, char16_t, char32_t, class, compl, const, constexpr, const_cast, continue, decltype, default, delete, do, double, dynamic_cast, else, enum, explicit, export, extern, false, float, for, friend, goto, if, inline, int, long, mutable, namespace, new, noexcept, not, not_eq, nullptr, operator, or, or_eq, private, protected, public, register, reinterpret_cast, return, short, signed, sizeof, static, static_assert, static_cast, struct, switch, template, this, thread_local, throw, true, try, typedef, typeid, typename, union, unsigned, using, virtual, void, volatile, wchar_t, while, xor, xor_eq
Specific compilers may also have additional specific reserved keywords.
Very important: The C++ language is a "case sensitive" language. That means that an identifier written in capital letters is not equivalent to another one with the same name but written in small letters. Thus, for example, the RESULT variable is not the same as the result variable or the Result variable. These are three different identifiers identifiying three different variables.Fundamental data types
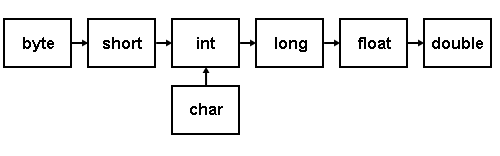
The values of variables are stored somewhere in an unspecified location in the computer memory as zeros and ones. Our program does not need to know the exact location where a variable is stored; it can simply refer to it by its name. What the program needs to be aware of is the kind of data stored in the variable. It's not the same to store a simple integer as it is to store a letter or a large floating-point number; even though they are all represented using zeros and ones, they are not interpreted in the same way, and in many cases, they don't occupy the same amount of memory.
Fundamental data types are basic types implemented directly by the language that represent the basic storage units supported natively by most systems. They can mainly be classified into:
- Character types: They can represent a single character, such as 'A' or '$'. The most basic type is char, which is a one-byte character. Other types are also provided for wider characters.
- Numerical integer types: They can store a whole number value, such as 7 or 1024. They exist in a variety of sizes, and can either be signed or unsigned, depending on whether they support negative values or not.
- Floating-point types: They can represent real values, such as 3.14 or 0.01, with different levels of precision, depending on which of the three floating-point types is used.
- Boolean type: The boolean type, known in C++ as bool, can only represent one of two states, true or false.
Here is the complete list of fundamental types in C++:
| Group | Type names* | Notes on size / precision |
|---|---|---|
| Character types | char | Exactly one byte in size. At least 8 bits. |
char16_t | Not smaller than char. At least 16 bits. | |
char32_t | Not smaller than char16_t. At least 32 bits. | |
wchar_t | Can represent the largest supported character set. | |
| Integer types (signed) | signed char | Same size as char. At least 8 bits. |
signed short int | Not smaller than char. At least 16 bits. | |
signed int | Not smaller than short. At least 16 bits. | |
signed long int | Not smaller than int. At least 32 bits. | |
signed long long int | Not smaller than long. At least 64 bits. | |
| Integer types (unsigned) | unsigned char | (same size as their signed counterparts) |
unsigned short int | ||
unsigned int | ||
unsigned long int | ||
unsigned long long int | ||
| Floating-point types | float | |
double | Precision not less than float | |
long double | Precision not less than double | |
| Boolean type | bool | |
| Void type | void | no storage |
| Null pointer | decltype(nullptr) |
* The names of certain integer types can be abbreviated without their signed and int components - only the part not in italics is required to identify the type, the part in italics is optional. I.e., signed short int can be abbreviated as signed short, short int, or simply short; they all identify the same fundamental type.
Within each of the groups above, the difference between types is only their size (i.e., how much they occupy in memory): the first type in each group is the smallest, and the last is the largest, with each type being at least as large as the one preceding it in the same group. Other than that, the types in a group have the same properties.
Note in the panel above that other than char (which has a size of exactly one byte), none of the fundamental types has a standard size specified (but a minimum size, at most). Therefore, the type is not required (and in many cases is not) exactly this minimum size. This does not mean that these types are of an undetermined size, but that there is no standard size across all compilers and machines; each compiler implementation may specify the sizes for these types that fit the best the architecture where the program is going to run. This rather generic size specification for types gives the C++ language a lot of flexibility to be adapted to work optimally in all kinds of platforms, both present and future.
Type sizes above are expressed in bits; the more bits a type has, the more distinct values it can represent, but at the same time, also consumes more space in memory:
| Size | Unique representable values | Notes |
|---|---|---|
| 8-bit | 256 | = 28 |
| 16-bit | 65 536 | = 216 |
| 32-bit | 4 294 967 296 | = 232 (~4 billion) |
| 64-bit | 18 446 744 073 709 551 616 | = 264 (~18 billion billion) |
For integer types, having more representable values means that the range of values they can represent is greater; for example, a 16-bit unsigned integer would be able to represent 65536 distinct values in the range 0 to 65535, while its signed counterpart would be able to represent, on most cases, values between -32768 and 32767. Note that the range of positive values is approximately halved in signed types compared to unsigned types, due to the fact that one of the 16 bits is used for the sign; this is a relatively modest difference in range, and seldom justifies the use of unsigned types based purely on the range of positive values they can represent.
For floating-point types, the size affects their precision, by having more or less bits for their significant and exponent.
If the size or precision of the type is not a concern, then char, int, and double are typically selected to represent characters, integers, and floating-point values, respectively. The other types in their respective groups are only used in very particular cases.
The properties of fundamental types in a particular system and compiler implementation can be obtained by using the numeric_limits classes (see standard header <limits>). If for some reason, types of specific sizes are needed, the library defines certain fixed-size type aliases in header <cstdint>.
The types described above (characters, integers, floating-point, and boolean) are collectively known as arithmetic types. But two additional fundamental types exist: void, which identifies the lack of type; and the type nullptr, which is a special type of pointer. Both types will be discussed further in a coming chapter about pointers.
C++ supports a wide variety of types based on the fundamental types discussed above; these other types are known as compound data types, and are one of the main strengths of the C++ language. We will also see them in more detail in future chapters.
Declaration of variables
C++ is a strongly-typed language, and requires every variable to be declared with its type before its first use. This informs the compiler the size to reserve in memory for the variable and how to interpret its value. The syntax to declare a new variable in C++ is straightforward: we simply write the type followed by the variable name (i.e., its identifier). For example:
int a;
float mynumber;
These are two valid declarations of variables. The first one declares a variable of type int with the identifier a. The second one declares a variable of type float with the identifier mynumber. Once declared, the variables a and mynumber can be used within the rest of their scope in the program. If declaring more than one variable of the same type, they can all be declared in a single statement by separating their identifiers with commas. For example:
int a, b, c;
This declares three variables (a, b and c), all of them of type int, and has exactly the same meaning as:
int a;
int b;
int c;
4
Don't be worried if something else than the variable declarations themselves look a bit strange to you. Most of it will be explained in more detail in coming chapters.
Initialization of variables
When the variables in the example above are declared, they have an undetermined value until they are assigned a value for the first time. But it is possible for a variable to have a specific value from the moment it is declared. This is called the initialization of the variable.
In C++, there are three ways to initialize variables. They are all equivalent and are reminiscent of the evolution of the language over the years:
The first one, known as c-like initialization (because it is inherited from the C language), consists of appending an equal sign followed by the value to which the variable is initialized:
type identifier = initial_value;
For example, to declare a variable of type int called x and initialize it to a value of zero from the same moment it is declared, we can write:
int x = 0;
A second method, known as constructor initialization (introduced by the C++ language), encloses the initial value between parentheses (()):
type identifier (initial_value);
For example:
int x (0);
Finally, a third method, known as uniform initialization, similar to the above, but using curly braces ({}) instead of parentheses (this was introduced by the revision of the C++ standard, in 2011):
type identifier {initial_value};
For example:
int x {0};
All three ways of initializing variables are valid and equivalent in C++.
6
Type deduction: auto and decltype
When a new variable is initialized, the compiler can figure out what the type of the variable is automatically by the initializer. For this, it suffices to use auto as the type specifier for the variable:
int foo = 0;auto bar = foo; // the same as: int bar = foo;
Here, bar is declared as having an auto type; therefore, the type of bar is the type of the value used to initialize it: in this case it uses the type of foo, which is int.
Variables that are not initialized can also make use of type deduction with the decltype specifier:
int foo = 0;decltype(foo) bar; // the same as: int bar;
Here, bar is declared as having the same type as foo.
auto and decltype are powerful features recently added to the language. But the type deduction features they introduce are meant to be used either when the type cannot be obtained by other means or when using it improves code readability. The two examples above were likely neither of these use cases. In fact they probably decreased readability, since, when reading the code, one has to search for the type of foo to actually know the type of bar.
Introduction to strings
Fundamental types represent the most basic types handled by the machines where the code may run. But one of the major strengths of the C++ language is its rich set of compound types, of which the fundamental types are mere building blocks. An example of compound type is the string class. Variables of this type are able to store sequences of characters, such as words or sentences. A very useful feature! A first difference with fundamental data types is that in order to declare and use objects (variables) of this type, the program needs to include the header where the type is defined within the standard library (header <tring>):
This is a string
As you can see in the previous example, strings can be initialized with any valid string literal, just like numerical type variables can be initialized to any valid numerical literal. As with fundamental types, all initialization formats are valid with strings:
string mystring = "This is a string";string mystring ("This is a string");string mystring {"This is a string"};Strings can also perform all the other basic operations that fundamental data types can, like being declared without an initial value and change its value during execution:
This is the initial string content
This is a different string content
The string class is a compound type. As you can see in the example above, compound types are used in the same way as fundamental types: the same syntax is used to declare variables and to initialize them.
4 - C++ CONSTANTS
Constants are expressions with a fixed value.Literals
Literals are the most obvious kind of constants. They are used to express particular values within the source code of a program. We have already used some in previous chapters to give specific values to variables or to express messages we wanted our programs to print out, for example, when we wrote:
a = 5;
The 5 in this piece of code was a literal constant.
Literal constants can be classified into: integer, floating-point, characters, strings, Boolean, pointers, and user-defined literals.
Integer Numerals
1776707-273These are numerical constants that identify integer values. Notice that they are not enclosed in quotes or any other special character; they are a simple succession of digits representing a whole number in decimal base; for example, 1776 always represents the value one thousand seven hundred seventy-six.
In addition to decimal numbers (those that most of us use every day), C++ allows the use of octal numbers (base 8) and hexadecimal numbers (base 16) as literal constants. For octal literals, the digits are preceded with a 0 (zero) character. And for hexadecimal, they are preceded by the characters 0x (zero, x). For example, the following literal constants are all equivalent to each other:
75 // decimal0113 // octal0x4b // hexadecimalAll of these represent the same number: 75 (seventy-five) expressed as a base-10 numeral, octal numeral and hexadecimal numeral, respectively.
These literal constants have a type, just like variables. By default, integer literals are of type int. However, certain suffixes may be appended to an integer literal to specify a different integer type:
| Suffix | Type modifier |
|---|---|
u or U | unsigned |
l or L | long |
ll or LL | long long |
Unsigned may be combined with any of the other two in any order to form unsigned long or unsigned long long.
For example:
In all the cases above, the suffix can be specified using either upper or lowercase letters.
Floating Point Numerals
They express real values, with decimals and/or exponents. They can include either a decimal point, an e character (that expresses "by ten at the Xth height", where X is an integer value that follows the e character), or both a decimal point and an e character:
These are four valid numbers with decimals expressed in C++. The first number is PI, the second one is the number of Avogadro, the third is the electric charge of an electron (an extremely small number) -all of them approximated-, and the last one is the number three expressed as a floating-point numeric literal.
The default type for floating-point literals is double. Floating-point literals of type float or long double can be specified by adding one of the following suffixes:
| Suffix | Type |
|---|---|
f or F | float |
l or L | long double |
For example:
Any of the letters that can be part of a floating-point numerical constant (e, f, l) can be written using either lower or uppercase letters with no difference in meaning.
Character and string literals
Character and string literals are enclosed in quotes:
The first two expressions represent single-character literals, and the following two represent string literals composed of several characters. Notice that to represent a single character, we enclose it between single quotes ('), and to express a string (which generally consists of more than one character), we enclose the characters between double quotes (").
Both single-character and string literals require quotation marks surrounding them to distinguish them from possible variable identifiers or reserved keywords. Notice the difference between these two expressions:
x
'x'
Here, x alone would refer to an identifier, such as the name of a variable or a compound type, whereas 'x' (enclosed within single quotation marks) would refer to the character literal 'x' (the character that represents a lowercase x letter).
Character and string literals can also represent special characters that are difficult or impossible to express otherwise in the source code of a program, like newline (\n) or tab (\t). These special characters are all of them preceded by a backslash character (\).
Here you have a list of the single character escape codes:
| Escape code | Description |
|---|---|
\n | newline |
\r | carriage return |
\t | tab |
\v | vertical tab |
\b | backspace |
\f | form feed (page feed) |
\a | alert (beep) |
\' | single quote (') |
\" | double quote (") |
\? | question mark (?) |
\\ | backslash (\) |
For example:
'\n'
'\t'
"Left \t Right"
"one\ntwo\nthree"
Internally, computers represent characters as numerical codes: most typically, they use one extension of the ASCII character encoding system (see ASCII code for more info). Characters can also be represented in literals using its numerical code by writing a backslash character (\) followed by the code expressed as an octal (base-8) or hexadecimal (base-16) number. For an octal value, the backslash is followed directly by the digits; while for hexadecimal, an x character is inserted between the backslash and the hexadecimal digits themselves (for example: \x20 or \x4A).
Several string literals can be concatenated to form a single string literal simply by separating them by one or more blank spaces, including tabs, newlines, and other valid blank characters. For example:
The above is a string literal equivalent to:
Note how spaces within the quotes are part of the literal, while those outside them are not.
Some programmers also use a trick to include long string literals in multiple lines: In C++, a backslash (\) at the end of line is considered a line-continuation character that merges both that line and the next into a single line. Therefore the following code:
is equivalent to:
All the character literals and string literals described above are made of characters of type char. A different character type can be specified by using one of the following prefixes:
| Prefix | Character type |
|---|---|
u | char16_t |
U | char32_t |
L | wchar_t |
Note that, unlike type suffixes for integer literals, these prefixes are case sensitive: lowercase for char16_t and uppercase for char32_t and wchar_t.
For string literals, apart from the above u, U, and L, two additional prefixes exist:
| Prefix | Description |
|---|---|
u8 | The string literal is encoded in the executable using UTF-8 |
R | The string literal is a raw string |
In raw strings, backslashes and single and double quotes are all valid characters; the content of the literal is delimited by an initial R"sequence( and a final )sequence", where sequence is any sequence of characters (including an empty sequence). The content of the string is what lies inside the parenthesis, ignoring the delimiting sequence itself. For example:
Both strings above are equivalent to "string with \\backslash". The R prefix can be combined with any other prefixes, such as u, L or u8.
Three keyword literals exist in C++: true, false and nullptr:
- true and false are the two possible values for variables of type bool.
- nullptr is the null pointer value.
Typed constant expressions
Sometimes, it is just convenient to give a name to a constant value:
We can then use these names instead of the literals they were defined to:
31.4159
Preprocessor definitions (#define)
Another mechanism to name constant values is the use of preprocessor definitions. They have the following form:
#define identifier replacement
After this directive, any occurrence of identifier in the code is interpreted as replacement, where replacement is any sequence of characters (until the end of the line). This replacement is performed by the preprocessor, and happens before the program is compiled, thus causing a sort of blind replacement: the validity of the types or syntax involved is not checked in any way.
For example:
31.4159
Note that the #define lines are preprocessor directives, and as such are single-line instructions that -unlike C++ statements- do not require semicolons (;) at the end; the directive extends automatically until the end of the line. If a semicolon is included in the line, it is part of the replacement sequence and is also included in all replaced occurrences.
1 - C++ OPERATORS
Once introduced to variables and constants, we can begin to operate with them by using operators. What follows is a complete list of operators. At this point, it is likely not necessary to know all of them, but they are all listed here to also serve as reference.
Assignment operator (=)
The assignment operator assigns a value to a variable.
x = 5;
This statement assigns the integer value 5 to the variable x. The assignment operation always takes place from right to left, and never the other way around:
x = y;
This statement assigns to variable x the value contained in variable y. The value of x at the moment this statement is executed is lost and replaced by the value of y.
Consider also that we are only assigning the value of y to x at the moment of the assignment operation. Therefore, if y changes at a later moment, it will not affect the new value taken by x.
For example, let's have a look at the following code - I have included the evolution of the content stored in the variables as comments:
a:4 b:7
This program prints on screen the final values of a and b (4 and 7, respectively). Notice how a was not affected by the final modification of b, even though we declared a = b earlier.
Assignment operations are expressions that can be evaluated. That means that the assignment itself has a value, and -for fundamental types- this value is the one assigned in the operation. For example:
y = 2 + (x = 5);
In this expression, y is assigned the result of adding 2 and the value of another assignment expression (which has itself a value of 5). It is roughly equivalent to:
x = 5;y = 2 + x;
With the final result of assigning 7 to y.
The following expression is also valid in C++:
y = y = z = 5;
It assigns 5 to the all three variables: x, y and z; always from right-to-left.
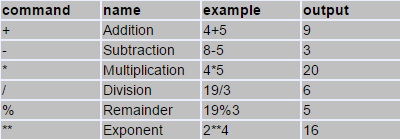
Arithmetic operators ( +, -, *, /, % )
The five arithmetical operations supported by C++ are:
Operations of addition, subtraction, multiplication and division correspond literally to their respective mathematical operators. The last one, modulo operator, represented by a percentage sign (%), gives the remainder of a division of two values. For example:
x = 11 % 3;
results in variable x containing the value 2, since dividing 11 by 3 results in 3, with a remainder of 2.
Compound assignment (+=, -=, *=, /=, %=, >>=, <<=, &=, ^=, |=)
Compound assignment operators modify the current value of a variable by performing an operation on it. They are equivalent to assigning the result of an operation to the first operand:
| expression | equivalent to... |
|---|---|
y += x; | y = y + x; |
x -= 5; | x = x - 5; |
x /= y; | x = x / y; |
price *= units + 1; | price = price * (units+1); |
and the same for all other compound assignment operators. For example:
Increment and decrement (++, --)
Some expression can be shortened even more: the increase operator (++) and the decrease operator (--) increase or reduce by one the value stored in a variable. They are equivalent to +=1 and to -=1, respectively. Thus:
are all equivalent in its functionality; the three of them increase by one the value of x.
In the early C compilers, the three previous expressions may have produced different executable code depending on which one was used. Nowadays, this type of code optimization is generally performed automatically by the compiler, thus the three expressions should produce exactly the same executable code.
A peculiarity of this operator is that it can be used both as a prefix and as a suffix. That means that it can be written either before the variable name (++x) or after it (x++). Although in simple expressions like x++ or ++x, both have exactly the same meaning; in other expressions in which the result of the increment or decrement operation is evaluated, they may have an important difference in their meaning: In the case that the increase operator is used as a prefix (++x) of the value, the expression evaluates to the final value of x, once it is already increased. On the other hand, in case that it is used as a suffix (x++), the value is also increased, but the expression evaluates to the value that x had before being increased. Notice the difference:
| Example 1 | Example 2 |
|---|---|
x = 3; |
x = 3; |
In Example 1, the value assigned to y is the value of x after being increased. While in Example 2, it is the value x had before being increased.
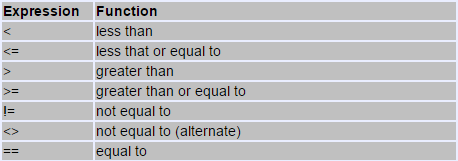
Relational and comparison operators ( ==, !=, >, <, >=, <= )
Two expressions can be compared using relational and equality operators. For example, to know if two values are equal or if one is greater than the other.
The result of such an operation is either true or false (i.e., a Boolean value).
The relational operators in C++ are:
| operator | description |
|---|---|
== | Equal to |
!= | Not equal to |
< | Less than |
> | Greater than |
<= | Less than or equal to |
>= | Greater than or equal to |
Here there are some examples:
Of course, it's not just numeric constants that can be compared, but just any value, including, of course, variables. Suppose that a=2, b=3 and c=6, then:
Be careful! The assignment operator (operator =, with one equal sign) is not the same as the equality comparison operator (operator ==, with two equal signs); the first one (=) assigns the value on the right-hand to the variable on its left, while the other (==) compares whether the values on both sides of the operator are equal. Therefore, in the last expression ((b=2) == a), we first assigned the value 2 to b and then we compared it to a (that also stores the value 2), yielding true.
Logical operators ( !, &&, || )
The operator ! is the C++ operator for the Boolean operation NOT. It has only one operand, to its right, and inverts it, producing false if its operand is true, and true if its operand is false. Basically, it returns the opposite Boolean value of evaluating its operand. For example:
The logical operators && and || are used when evaluating two expressions to obtain a single relational result. The operator && corresponds to the Boolean logical operation AND, which yields true if both its operands are true, and false otherwise. The following panel shows the result of operator && evaluating the expression a&&b:
| && OPERATOR (and) | ||
|---|---|---|
a | b | a && b |
true | true | true |
true | false | false |
false | true | false |
false | false | false |
The operator || corresponds to the Boolean logical operation OR, which yields true if either of its operands is true, thus being false only when both operands are false. Here are the possible results of a||b:
| || OPERATOR (or) | ||
|---|---|---|
a | b | a || b |
true | true | true |
true | false | true |
false | true | true |
false | false | false |
When using the logical operators, C++ only evaluates what is necessary from left to right to come up with the combined relational result, ignoring the rest. Therefore, in the last example ((5==5)||(3>6)), C++ evaluates first whether 5==5 is true, and if so, it never checks whether 3>6 is true or not. This is known as short-circuit evaluation, and works like this for these operators:
| operator | short-circuit |
|---|---|
&& | if the left-hand side expression is false, the combined result is false (the right-hand side expression is never evaluated). |
|| | if the left-hand side expression is true, the combined result is true (the right-hand side expression is never evaluated). |
This is mostly important when the right-hand expression has side effects, such as altering values:
Here, the combined conditional expression would increase i by one, but only if the condition on the left of && is true, because otherwise, the condition on the right-hand side (++i<n) is never evaluated.
Conditional ternary operator ( ? )
The conditional operator evaluates an expression, returning one value if that expression evaluates to true, and a different one if the expression evaluates as false. Its syntax is:
condition ? result1 : result2
If condition is true, the entire expression evaluates to result1, and otherwise to result2.
For example:
7
In this example, a was 2, and b was 7, so the expression being evaluated (a>b) was not true, thus the first value specified after the question mark was discarded in favor of the second value (the one after the colon) which was b (with a value of 7).
Comma operator ( , )
The comma operator (,) is used to separate two or more expressions that are included where only one expression is expected. When the set of expressions has to be evaluated for a value, only the right-most expression is considered.
For example, the following code:
a = (b=3, b+2);
would first assign the value 3 to b, and then assign b+2 to variable a. So, at the end, variable a would contain the value 5 while variable b would contain value 3.
Bitwise operators ( &, |, ^, ~, <<, >> )
Bitwise operators modify variables considering the bit patterns that represent the values they store.
| operator | asm equivalent | description |
|---|---|---|
& | AND | Bitwise AND |
| | OR | Bitwise inclusive OR |
^ | XOR | Bitwise exclusive OR |
~ | NOT | Unary complement (bit inversion) |
<< | SHL | Shift bits left |
>> | SHR | Shift bits right |
Explicit type casting operator
Type casting operators allow to convert a value of a given type to another type. There are several ways to do this in C++. The simplest one, which has been inherited from the C language, is to precede the expression to be converted by the new type enclosed between parentheses (()):
The previous code converts the floating-point number 3.14 to an integer value (3); the remainder is lost. Here, the typecasting operator was (int). Another way to do the same thing in C++ is to use the functional notation preceding the expression to be converted by the type and enclosing the expression between parentheses:
Both ways of casting types are valid in C++.
sizeof
This operator accepts one parameter, which can be either a type or a variable, and returns the size in bytes of that type or object:
Here, x is assigned the value 1, because char is a type with a size of one byte.
The value returned by sizeof is a compile-time constant, so it is always determined before program execution.
Other operators
Later in these tutorials, we will see a few more operators, like the ones referring to pointers or the specifics for object-oriented programming.
Precedence of operators
A single expression may have multiple operators. For example:
In C++, the above expression always assigns 6 to variable x, because the % operator has a higher precedence than the + operator, and is always evaluated before. Parts of the expressions can be enclosed in parenthesis to override this precedence order, or to make explicitly clear the intended effect. Notice the difference:
From greatest to smallest priority, C++ operators are evaluated in the following order:
| Level | Precedence group | Operator | Description | Grouping |
|---|---|---|---|---|
| 1 | Scope | :: | scope qualifier | Left-to-right |
| 2 | Postfix (unary) | ++ -- | postfix increment / decrement | Left-to-right |
() | functional forms | |||
[] | subscript | |||
. -> | member access | |||
| 3 | Prefix (unary) | ++ -- | prefix increment / decrement | Right-to-left |
~ ! | bitwise NOT / logical NOT | |||
+ - | unary prefix | |||
& * | reference / dereference | |||
new delete | allocation / deallocation | |||
sizeof | parameter pack | |||
(type) | C-style type-casting | |||
| 4 | Pointer-to-member | .* ->* | access pointer | Left-to-right |
| 5 | Arithmetic: scaling | * / % | multiply, divide, modulo | Left-to-right |
| 6 | Arithmetic: addition | + - | addition, subtraction | Left-to-right |
| 7 | Bitwise shift | << >> | shift left, shift right | Left-to-right |
| 8 | Relational | < > <= >= | comparison operators | Left-to-right |
| 9 | Equality | == != | equality / inequality | Left-to-right |
| 10 | And | & | bitwise AND | Left-to-right |
| 11 | Exclusive or | ^ | bitwise XOR | Left-to-right |
| 12 | Inclusive or | | | bitwise OR | Left-to-right |
| 13 | Conjunction | && | logical AND | Left-to-right |
| 14 | Disjunction | || | logical OR | Left-to-right |
| 15 | Assignment-level expressions | = *= /= %= += -= | assignment / compound assignment | Right-to-left |
?: | conditional operator | |||
| 16 | Sequencing | , | comma separator | Left-to-right |
When an expression has two operators with the same precedence level, grouping determines which one is evaluated first: either left-to-right or right-to-left.
5 - C++ INPUT / OUPUT
The example programs of the previous sections provided little interaction with the user, if any at all. They simply printed simple values on screen, but the standard library provides many additional ways to interact with the user via its input/output features. This section will present a short introduction to some of the most useful.
C++ uses a convenient abstraction called streams to perform input and output operations in sequential media such as the screen, the keyboard or a file. A stream is an entity where a program can either insert or extract characters to/from. There is no need to know details about the media associated to the stream or any of its internal specifications. All we need to know is that streams are a source/destination of characters, and that these characters are provided/accepted sequentially (i.e., one after another).
The standard library defines a handful of stream objects that can be used to access what are considered the standard sources and destinations of characters by the environment where the program runs:
| stream | description |
|---|---|
cin | standard input stream |
cout | standard output stream |
cerr | standard error (output) stream |
clog | standard logging (output) stream |
We are going to see in more detail only cout and cin (the standard output and input streams); cerr and clog are also output streams, so they essentially work like cout, with the only difference being that they identify streams for specific purposes: error messages and logging; which, in many cases, in most environment setups, they actually do the exact same thing: they print on screen, although they can also be individually redirected.
Standard output (cout)
On most program environments, the standard output by default is the screen, and the C++ stream object defined to access it is cout.
For formatted output operations, cout is used together with the insertion operator, which is written as << (i.e., two "less than" signs).
The << operator inserts the data that follows it into the stream that precedes it. In the examples above, it inserted the literal string Output sentence, the number 120, and the value of variable x into the standard output stream cout. Notice that the sentence in the first statement is enclosed in double quotes (") because it is a string literal, while in the last one, x is not. The double quoting is what makes the difference; when the text is enclosed between them, the text is printed literally; when they are not, the text is interpreted as the identifier of a variable, and its value is printed instead. For example, these two sentences have very different results:
Multiple insertion operations (<<) may be chained in a single statement:
This last statement would print the text This is a single C++ statement. Chaining insertions is especially useful to mix literals and variables in a single statement:
Assuming the age variable contains the value 24 and the zipcode variable contains 90064, the output of the previous statement would be: I am 24 years old and my zipcode is 90064 What cout does not do automatically is add line breaks at the end, unless instructed to do so. For example, take the following two statements inserting into cout: cout << "This is a sentence."; cout << "This is another sentence."; The output would be in a single line, without any line breaks in between. Something like: This is a sentence.This is another sentence. To insert a line break, a new-line character shall be inserted at the exact position the line should be broken. In C++, a new-line character can be specified as \n (i.e., a backslash character followed by a lowercase n). For example:
This produces the following output:
First sentence.
Second sentence.
Third sentence.
Alternatively, the endl manipulator can also be used to break lines. For example:
This would print:
First sentence.
Second sentence.
The endl manipulator produces a newline character, exactly as the insertion of '\n' does; but it also has an additional behavior: the stream's buffer (if any) is flushed, which means that the output is requested to be physically written to the device, if it wasn't already. This affects mainly fully buffered streams, and cout is (generally) not a fully buffered stream. Still, it is generally a good idea to use endl only when flushing the stream would be a feature and '\n' when it would not. Bear in mind that a flushing operation incurs a certain overhead, and on some devices it may produce a delay.
Standard input (cin)
In most program environments, the standard input by default is the keyboard, and the C++ stream object defined to access it is cin.
For formatted input operations, cin is used together with the extraction operator, which is written as >> (i.e., two "greater than" signs). This operator is then followed by the variable where the extracted data is stored. For example:
The first statement declares a variable of type int called age, and the second extracts from cin a value to be stored in it. This operation makes the program wait for input from cin; generally, this means that the program will wait for the user to enter some sequence with the keyboard. In this case, note that the characters introduced using the keyboard are only transmitted to the program when the ENTER (or RETURN) key is pressed. Once the statement with the extraction operation on cin is reached, the program will wait for as long as needed until some input is introduced.
The extraction operation on cin uses the type of the variable after the >> operator to determine how it interprets the characters read from the input; if it is an integer, the format expected is a series of digits, if a string a sequence of characters, etc.
As you can see, extracting from cin seems to make the task of getting input from the standard input pretty simple and straightforward. But this method also has a big drawback. What happens in the example above if the user enters something else that cannot be interpreted as an integer? Well, in this case, the extraction operation fails. And this, by default, lets the program continue without setting a value for variable i, producing undetermined results if the value of i is used later.
This is very poor program behavior. Most programs are expected to behave in an expected manner no matter what the user types, handling invalid values appropriately. Only very simple programs should rely on values extracted directly from cin without further checking. A little later we will see how stringstreams can be used to have better control over user input.
Extractions on cin can also be chained to request more than one datum in a single statement:
This is equivalent to:
In both cases, the user is expected to introduce two values, one for variable a, and another for variable b. Any kind of space is used to separate two consecutive input operations; this may either be a space, a tab, or a new-line character.
cin and strings
The extraction operator can be used on cin to get strings of characters in the same way as with fundamental data types:
However, cin extraction always considers spaces (whitespaces, tabs, new-line...) as terminating the value being extracted, and thus extracting a string means to always extract a single word, not a phrase or an entire sentence.
To get an entire line from cin, there exists a function, called getline, that takes the stream (cin) as first argument, and the string variable as second. For example:
What's your name? Homer Simpson
Hello Homer Simpson.
What is your favorite team? The Isotopes
I like The Isotopes too!
Notice how in both calls to getline, we used the same string identifier (mystr). What the program does in the second call is simply replace the previous content with the new one that is introduced.
The standard behavior that most users expect from a console program is that each time the program queries the user for input, the user introduces the field, and then presses ENTER (or RETURN). That is to say, input is generally expected to happen in terms of lines on console programs, and this can be achieved by using getline to obtain input from the user. Therefore, unless you have a strong reason not to, you should always use getline to get input in your console programs instead of extracting from cin.
stringstream
The standard header <sstream> defines a type called stringstream that allows a string to be treated as a stream, and thus allowing extraction or insertion operations from/to strings in the same way as they are performed on cin and cout. This feature is most useful to convert strings to numerical values and vice versa. For example, in order to extract an integer from a string we can write:
This declares a string with initialized to a value of "1204", and a variable of type int. Then, the third line uses this variable to extract from a stringstream constructed from the string. This piece of code stores the numerical value 1204 in the variable called myint.
Enter price: 22.25 Enter quantity: 7 Total price: 155.75
In this example, we acquire numeric values from the standard input indirectly: Instead of extracting numeric values directly from cin, we get lines from it into a string object (mystr), and then we extract the values from this string into the variables price and quantity. Once these are numerical values, arithmetic operations can be performed on them, such as multiplying them to obtain a total price.
With this approach of getting entire lines and extracting their contents, we separate the process of getting user input from its interpretation as data, allowing the input process to be what the user expects, and at the same time gaining more control over the transformation of its content into useful data by the program.
6 - C++ CONTROL STRUCTURE
Statements and flow control
A simple C++ statement is each of the individual instructions of a program, like the variable declarations and expressions seen in previous sections. They always end with a semicolon (;), and are executed in the same order in which they appear in a program.
But programs are not limited to a linear sequence of statements. During its process, a program may repeat segments of code, or take decisions and bifurcate. For that purpose, C++ provides flow control statements that serve to specify what has to be done by our program, when, and under which circumstances.
Many of the flow control statements explained in this section require a generic (sub)statement as part of its syntax. This statement may either be a simple C++ statement, -such as a single instruction, terminated with a semicolon (;) - or a compound statement. A compound statement is a group of statements (each of them terminated by its own semicolon), but all grouped together in a block, enclosed in curly braces: {}:
{ statement1; statement2; statement3; }
The entire block is considered a single statement (composed itself of multiple substatements). Whenever a generic statement is part of the syntax of a flow control statement, this can either be a simple statement or a compound statement.
Selection statements: if and else
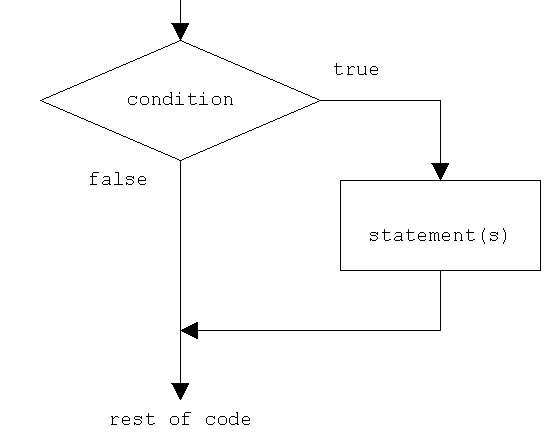
The if keyword is used to execute a statement or block, if, and only if, a condition is fulfilled. Its syntax is:
if (condition) statement
Here, condition is the expression that is being evaluated. If this condition is true, statement is executed. If it is false, statement is not executed (it is simply ignored), and the program continues right after the entire selection statement.
For example, the following code fragment prints the message (x is 100), only if the value stored in the x variable is indeed 100:
If x is not exactly 100, this statement is ignored, and nothing is printed.
If you want to include more than a single statement to be executed when the condition is fulfilled, these statements shall be enclosed in braces ({}), forming a block:
As usual, indentation and line breaks in the code have no effect, so the above code is equivalent to:
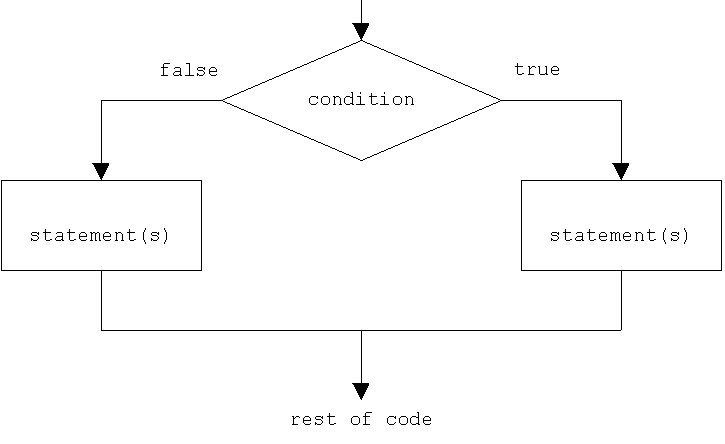
Selection statements with if can also specify what happens when the condition is not fulfilled, by using the else keyword to introduce an alternative statement. Its syntax is:
if (condition) statement1 else statement2
where statement1 is executed in case condition is true, and in case it is not, statement2 is executed.
For example:
This prints x is 100, if indeed x has a value of 100, but if it does not, and only if it does not, it prints x is not 100 instead.
Several if + else structures can be concatenated with the intention of checking a range of values. For example:
This prints whether x is positive, negative, or zero by concatenating two if-else structures. Again, it would have also been possible to execute more than a single statement per case by grouping them into blocks enclosed in braces: {}.
Iteration statements (loops)
Loops repeat a statement a certain number of times, or while a condition is fulfilled. They are introduced by the keywords while, do, and for.
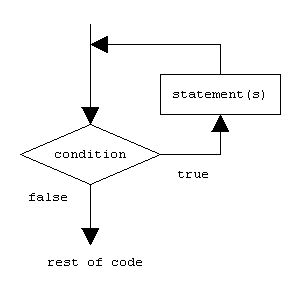
The while loop
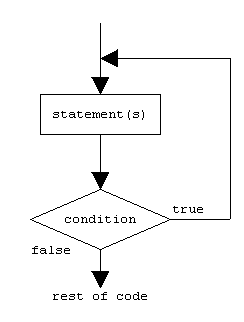
The simplest kind of loop is the while-loop. Its syntax is:
while (expression) statement
The while-loop simply repeats statement while expression is true. If, after any execution of statement, expression is no longer true, the loop ends, and the program continues right after the loop. For example, let's have a look at a countdown using a while-loop:
The first statement in main sets n to a value of 10. This is the first number in the countdown. Then the while-loop begins: if this value fulfills the condition n>0 (that n is greater than zero), then the block that follows the condition is executed, and repeated for as long as the condition (n>0) remains being true.
The whole process of the previous program can be interpreted according to the following script (beginning in main):
- n is assigned a value
- The while condition is checked (n>0). At this point there are two possibilities:
- condition is true: the statement is executed (to step 3)
- condition is false: ignore statement and continue after it (to step 5)
- Execute statement:
cout << n << ", ";
--n;
(prints the value of n and decreases n by 1)
- End of block. Return automatically to step 2.
- Continue the program right after the block:
print liftoff! and end the program.
A thing to consider with while-loops is that the loop should end at some point, and thus the statement shall alter values checked in the condition in some way, so as to force it to become false at some point. Otherwise, the loop will continue looping forever. In this case, the loop includes --n, that decreases the value of the variable that is being evaluated in the condition (n) by one - this will eventually make the condition (n>0) false after a certain number of loop iterations. To be more specific, after 10 iterations, n becomes 0, making the condition no longer true, and ending the while-loop.
Note that the complexity of this loop is trivial for a computer, and so the whole countdown is performed instantly, without any practical delay between elements of the count (if interested, see sleep_for for a countdown example with delays).
The do-while loop
A very similar loop is the do-while loop, whose syntax is:
do statement while (condition);
It behaves like a while-loop, except that condition is evaluated after the execution of statement instead of before, guaranteeing at least one execution of statement, even if condition is never fulfilled. For example, the following example program echoes any text the user introduces until the user enters goodbye:
Enter text: hello
You entered: hello
Enter text: who's there?
You entered: who's there?
Enter text: goodbye
You entered: goodbye
The do-while loop is usually preferred over a while-loop when the statement needs to be executed at least once, such as when the condition that is checked to end of the loop is determined within the loop statement itself. In the previous example, the user input within the block is what will determine if the loop ends. And thus, even if the user wants to end the loop as soon as possible by entering goodbye, the block in the loop needs to be executed at least once to prompt for input, and the condition can, in fact, only be determined after it is executed.
The for loop
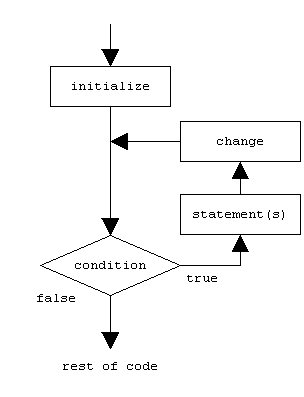
The for loop is designed to iterate a number of times. Its syntax is:
for (initialization; condition; increase) statement;
Like the while-loop, this loop repeats statement while condition is true. But, in addition, the for loop provides specific locations to contain an initialization and an increase expression, executed before the loop begins the first time, and after each iteration, respectively. Therefore, it is especially useful to use counter variables as condition.
It works in the following way:
- initialization is executed. Generally, this declares a counter variable, and sets it to some initial value. This is executed a single time, at the beginning of the loop.
- condition is checked. If it is true, the loop continues; otherwise, the loop ends, and statement is skipped, going directly to step 5.
- statement is executed. As usual, it can be either a single statement or a block enclosed in curly braces { }.
- increase is executed, and the loop gets back to step 2.
- the loop ends: execution continues by the next statement after it.
Here is the countdown example using a for loop:
10, 9, 8, 7, 6, 5, 4, 3, 2, 1, liftoff!
The three fields in a for-loop are optional. They can be left empty, but in all cases the semicolon signs between them are required. For example, for (;n<10;) is a loop without initialization or increase (equivalent to a while-loop); and for (;n<10;++n) is a loop with increase, but no initialization (maybe because the variable was already initialized before the loop). A loop with no condition is equivalent to a loop with true as condition (i.e., an infinite loop).
Because each of the fields is executed in a particular time in the life cycle of a loop, it may be useful to execute more than a single expression as any of initialization, condition, or statement. Unfortunately, these are not statements, but rather, simple expressions, and thus cannot be replaced by a block. As expressions, they can, however, make use of the comma operator (,): This operator is an expression separator, and can separate multiple expressions where only one is generally expected. For example, using it, it would be possible for a for loop to handle two counter variables, initializing and increasing both:
This loop will execute 50 times if neither n or i are modified within the loop:

n starts with a value of 0, and i with 100, the condition is n!=i (i.e., that n is not equal to i). Because n is increased by one, and i decreased by one on each iteration, the loop's condition will become false after the 50th iteration, when both n and i are equal to 50.
Range-based for loop
The for-loop has another syntax, which is used exclusively with ranges:
for ( declaration : range ) statement;
This kind of for loop iterates over all the elements in range, where declaration declares some variable able to take the value of an element in this range. Ranges are sequences of elements, including arrays, containers, and any other type supporting the functions begin and end; Most of these types have not yet been introduced in this tutorial, but we are already acquainted with at least one kind of range: strings, which are sequences of characters.
An example of range-based for loop using strings:
[H][e][l][l][o][!]
Note how what precedes the colon (:) in the for loop is the declaration of a char variable (the elements in a string are of type char). We then use this variable, c, in the statement block to represent the value of each of the elements in the range.
This loop is automatic and does not require the explicit declaration of any counter variable.
Range based loops usually also make use of type deduction for the type of the elements with auto. Typically, the range-based loop above can also be written as:
Here, the type of c is automatically deduced as the type of the elements in str.
Jump statements
Jump statements allow altering the flow of a program by performing jumps to specific locations.
The break statement
break leaves a loop, even if the condition for its end is not fulfilled. It can be used to end an infinite loop, or to force it to end before its natural end. For example, let's stop the countdown before its natural end:
10, 9, 8, 7, 6, 5, 4, 3, countdown aborted!
The continue statementThe continue statement causes the program to skip the rest of the loop in the current iteration, as if the end of the statement block had been reached, causing it to jump to the start of the following iteration. For example, let's skip number 5 in our countdown:
10, 9, 8, 7, 6, 4, 3, 2, 1, liftoff!
The goto statementgoto allows to make an absolute jump to another point in the program. This unconditional jump ignores nesting levels, and does not cause any automatic stack unwinding. Therefore, it is a feature to use with care, and preferably within the same block of statements, especially in the presence of local variables.
The destination point is identified by a label, which is then used as an argument for the goto statement. A label is made of a valid identifier followed by a colon (:).
goto is generally deemed a low-level feature, with no particular use cases in modern higher-level programming paradigms generally used with C++. But, just as an example, here is a version of our countdown loop using goto:
10, 9, 8, 7, 6, 5, 4, 3, 2, 1, liftoff!
Another selection statement: switch.
The syntax of the switch statement is a bit peculiar. Its purpose is to check for a value among a number of possible constant expressions. It is something similar to concatenating if-else statements, but limited to constant expressions. Its most typical syntax is:
It works in the following way: switch evaluates expression and checks if it is equivalent to constant1; if it is, it executes group-of-statements-1 until it finds the break statement. When it finds this break statement, the program jumps to the end of the entire switch statement (the closing brace).
If expression was not equal to constant1, it is then checked against constant2. If it is equal to this, it executes group-of-statements-2 until a break is found, when it jumps to the end of the switch.
Finally, if the value of expression did not match any of the previously specified constants (there may be any number of these), the program executes the statements included after the default: label, if it exists (since it is optional).
Both of the following code fragments have the same behavior, demonstrating the if-else equivalent of a switch statement:
| switch example | if-else equivalent |
|---|---|
|
|
The switch statement has a somewhat peculiar syntax inherited from the early times of the first C compilers, because it uses labels instead of blocks. In the most typical use (shown above), this means that break statements are needed after each group of statements for a particular label. If break is not included, all statements following the case (including those under any other labels) are also executed, until the end of the switch block or a jump statement (such as break) is reached.
If the example above lacked the break statement after the first group for case one, the program would not jump automatically to the end of the switch block after printing x is 1, and would instead continue executing the statements in case two (thus printing also x is 2). It would then continue doing so until a break statement is encountered, or the end of the switch block. This makes unnecessary to enclose the statements for each case in braces {}, and can also be useful to execute the same group of statements for different possible values. For example:
Notice that switch is limited to compare its evaluated expression against labels that are constant expressions. It is not possible to use variables as labels or ranges, because they are not valid C++ constant expressions.
7 - C++ FUNCTIONS
Functions allow to structure programs in segments of code to perform individual tasks.
In C++, a function is a group of statements that is given a name, and which can be called from some point of the program. The most common syntax to define a function is:
type name ( parameter1, parameter2, ...) { statements }
Where:
- type is the type of the value returned by the function.
- name is the identifier by which the function can be called.
- parameters (as many as needed): Each parameter consists of a type followed by an identifier, with each parameter being separated from the next by a comma. Each parameter looks very much like a regular variable declaration (for example: int x), and in fact acts within the function as a regular variable which is local to the function. The purpose of parameters is to allow passing arguments to the function from the location where it is called from.
- statements is the function's body. It is a block of statements surrounded by braces { } that specify what the function actually does.
Let's have a look at an example:
The result is 8
This program is divided in two functions: addition and main. Remember that no matter the order in which they are defined, a C++ program always starts by calling main. In fact, main is the only function called automatically, and the code in any other function is only executed if its function is called from main (directly or indirectly).
In the example above, main begins by declaring the variable z of type int, and right after that, it performs the first function call: it calls addition. The call to a function follows a structure very similar to its declaration. In the example above, the call to addition can be compared to its definition just a few lines earlier:

The parameters in the function declaration have a clear correspondence to the arguments passed in the function call. The call passes two values, 5 and 3, to the function; these correspond to the parameters a and b, declared for function addition.
At the point at which the function is called from within main, the control is passed to function addition: here, execution of main is stopped, and will only resume once the addition function ends. At the moment of the function call, the value of both arguments (5 and 3) are copied to the local variables int a and int b within the function.
Then, inside addition, another local variable is declared (int r), and by means of the expression r=a+b, the result of a plus b is assigned to r; which, for this case, where a is 5 and b is 3, means that 8 is assigned to r.
The final statement within the function:
return r;
Ends function addition, and returns the control back to the point where the function was called; in this case: to function main. At this precise moment, the program resumes its course on main returning exactly at the same point at which it was interrupted by the call to addition. But additionally, because addition has a return type, the call is evaluated as having a value, and this value is the value specified in the return statement that ended addition: in this particular case, the value of the local variable r, which at the moment of the return statement had a value of 8.
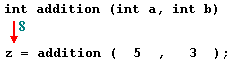
Therefore, the call to addition is an expression with the value returned by the function, and in this case, that value, 8, is assigned to z. It is as if the entire function call (addition(5,3)) was replaced by the value it returns (i.e., 8).
Then main simply prints this value by calling:
cout << "The result is " << z;
A function can actually be called multiple times within a program, and its argument is naturally not limited just to literals:
The first result is 5
The second result is 5
The third result is 2
The fourth result is 6
Similar to the addition function in the previous example, this example defines a subtract function, that simply returns the difference between its two parameters. This time, main calls this function several times, demonstrating more possible ways in which a function can be called.
Let's examine each of these calls, bearing in mind that each function call is itself an expression that is evaluated as the value it returns. Again, you can think of it as if the function call was itself replaced by the returned value:
If we replace the function call by the value it returns (i.e., 5), we would have:
With the same procedure, we could interpret:
as:
since 5 is the value returned by subtraction (7,2).
In the case of:
The arguments passed to subtraction are variables instead of literals. That is also valid, and works fine. The function is called with the values x and y have at the moment of the call: 5 and 3 respectively, returning 2 as result.
The fourth call is again similar:
The only addition being that now the function call is also an operand of an addition operation. Again, the result is the same as if the function call was replaced by its result: 6. Note, that thanks to the commutative property of additions, the above can also be written as:
With exactly the same result. Note also that the semicolon does not necessarily go after the function call, but, as always, at the end of the whole statement. Again, the logic behind may be easily seen again by replacing the function calls by their returned value:
Functions with no type. The use of void
he syntax shown above for functions:
type name ( argument1, argument2 ...) { statements }
Requires the declaration to begin with a type. This is the type of the value returned by the function. But what if the function does not need to return a value? In this case, the type to be used is void, which is a special type to represent the absence of value. For example, a function that simply prints a message may not need to return any value:
I'm a function!
void can also be used in the function's parameter list to explicitly specify that the function takes no actual parameters when called. For example, printmessage could have been declared as:
In C++, an empty parameter list can be used instead of void with same meaning, but the use of void in the argument list was popularized by the C language, where this is a requirement.
Something that in no case is optional are the parentheses that follow the function name, neither in its declaration nor when calling it. And even when the function takes no parameters, at least an empty pair of parentheses shall always be appended to the function name. See how printmessage was called in an earlier example:
printmessage ();
The parentheses are what differentiate functions from other kinds of declarations or statements. The following would not call the function:
printmessage;
The return value of main
You may have noticed that the return type of main is int, but most examples in this and earlier chapters did not actually return any value from main.
Well, there is a catch: If the execution of main ends normally without encountering a return statement the compiler assumes the function ends with an implicit return statement:
Note that this only applies to function main for historical reasons. All other functions with a return type shall end with a proper return statement that includes a return value, even if this is never used.
When main returns zero (either implicitly or explicitly), it is interpreted by the environment as that the program ended successfully. Other values may be returned by main, and some environments give access to that value to the caller in some way, although this behavior is not required nor necessarily portable between platforms. The values for main that are guaranteed to be interpreted in the same way on all platforms are:
| value | description |
|---|---|
0 | The program was successful |
EXIT_SUCCESS | The program was successful (same as above). This value is defined in header <cstdlib>. |
EXIT_FAILURE | The program failed. This value is defined in header <cstdlib>. |
Because the implicit return 0; statement for main is a tricky exception, some authors consider it good practice to explicitly write the statement.
Arguments passed by value and by reference
In the functions seen earlier, arguments have always been passed by value. This means that, when calling a function, what is passed to the function are the values of these arguments on the moment of the call, which are copied into the variables represented by the function parameters. For example, take:
In this case, function addition is passed 5 and 3, which are copies of the values of x and y, respectively. These values (5 and 3) are used to initialize the variables set as parameters in the function's definition, but any modification of these variables within the function has no effect on the values of the variables x and y outside it, because x and y were themselves not passed to the function on the call, but only copies of their values at that moment.
In certain cases, though, it may be useful to access an external variable from within a function. To do that, arguments can be passed by reference, instead of by value. For example, the function duplicate in this code duplicates the value of its three arguments, causing the variables used as arguments to actually be modified by the call:
x=2, y=6, z=14
To gain access to its arguments, the function declares its parameters as references. In C++, references are indicated with an ampersand (&) following the parameter type, as in the parameters taken by duplicate in the example above.
When a variable is passed by reference, what is passed is no longer a copy, but the variable itself, the variable identified by the function parameter, becomes somehow associated with the argument passed to the function, and any modification on their corresponding local variables within the function are reflected in the variables passed as arguments in the call.
In fact, a, b, and c become aliases of the arguments passed on the function call (x, y, and z) and any change on a within the function is actually modifying variable x outside the function. Any change on b modifies y, and any change on c modifies z. That is why when, in the example, function duplicate modifies the values of variables a, b, and c, the values of x, y, and z are affected.
If instead of defining duplicate as:
Was it to be defined without the ampersand signs as:
The variables would not be passed by reference, but by value, creating instead copies of their values. In this case, the output of the program would have been the values of x, y, and z without being modified (i.e., 1, 3, and 7).
Efficiency considerations and const references
Calling a function with parameters taken by value causes copies of the values to be made. This is a relatively inexpensive operation for fundamental types such as int, but if the parameter is of a large compound type, it may result on certain overhead. For example, consider the following function:
This function takes two strings as parameters (by value), and returns the result of concatenating them. By passing the arguments by value, the function forces a and b to be copies of the arguments passed to the function when it is called. And if these are long strings, it may mean copying large quantities of data just for the function call.
But this copy can be avoided altogether if both parameters are made references:
Arguments by reference do not require a copy. The function operates directly on (aliases of) the strings passed as arguments, and, at most, it might mean the transfer of certain pointers to the function. In this regard, the version of concatenate taking references is more efficient than the version taking values, since it does not need to copy expensive-to-copy strings.
On the flip side, functions with reference parameters are generally perceived as functions that modify the arguments passed, because that is why reference parameters are actually for.
The solution is for the function to guarantee that its reference parameters are not going to be modified by this function. This can be done by qualifying the parameters as constant:
By qualifying them as const, the function is forbidden to modify the values of neither a nor b, but can actually access their values as references (aliases of the arguments), without having to make actual copies of the strings.
Therefore, const references provide functionality similar to passing arguments by value, but with an increased efficiency for parameters of large types. That is why they are extremely popular in C++ for arguments of compound types. Note though, that for most fundamental types, there is no noticeable difference in efficiency, and in some cases, const references may even be less efficient!
Inline functions
Calling a function generally causes a certain overhead (stacking arguments, jumps, etc...), and thus for very short functions, it may be more efficient to simply insert the code of the function where it is called, instead of performing the process of formally calling a function.
Preceding a function declaration with the inline specifier informs the compiler that inline expansion is preferred over the usual function call mechanism for a specific function. This does not change at all the behavior of a function, but is merely used to suggest the compiler that the code generated by the function body shall be inserted at each point the function is called, instead of being invoked with a regular function call.
For example, the concatenate function above may be declared inline as:
This informs the compiler that when concatenate is called, the program prefers the function to be expanded inline, instead of performing a regular call. inline is only specified in the function declaration, not when it is called.
Note that most compilers already optimize code to generate inline functions when they see an opportunity to improve efficiency, even if not explicitly marked with the inline specifier. Therefore, this specifier merely indicates the compiler that inline is preferred for this function, although the compiler is free to not inline it, and optimize otherwise. In C++, optimization is a task delegated to the compiler, which is free to generate any code for as long as the resulting behavior is the one specified by the code.
Default values in parameters
In C++, functions can also have optional parameters, for which no arguments are required in the call, in such a way that, for example, a function with three parameters may be called with only two. For this, the function shall include a default value for its last parameter, which is used by the function when called with fewer arguments. For example:
6
5
In this example, there are two calls to function divide. In the first one:
divide (12)
The call only passes one argument to the function, even though the function has two parameters. In this case, the function assumes the second parameter to be 2 (notice the function definition, which declares its second parameter as int b=2). Therefore, the result is 6.
In the second call:
divide (20,4)
The call passes two arguments to the function. Therefore, the default value for b (int b=2) is ignored, and b takes the value passed as argument, that is 4, yielding a result of 5.
Declaring functions
In C++, identifiers can only be used in expressions once they have been declared. For example, some variable x cannot be used before being declared with a statement, such as:
int x;
The same applies to functions. Functions cannot be called before they are declared. That is why, in all the previous examples of functions, the functions were always defined before the main function, which is the function from where the other functions were called. If main were defined before the other functions, this would break the rule that functions shall be declared before being used, and thus would not compile.
The prototype of a function can be declared without actually defining the function completely, giving just enough details to allow the types involved in a function call to be known. Naturally, the function shall be defined somewhere else, like later in the code. But at least, once declared like this, it can already be called.
The declaration shall include all types involved (the return type and the type of its arguments), using the same syntax as used in the definition of the function, but replacing the body of the function (the block of statements) with an ending semicolon.
The parameter list does not need to include the parameter names, but only their types. Parameter names can nevertheless be specified, but they are optional, and do not need to necessarily match those in the function definition. For example, a function called protofunction with two int parameters can be declared with either of these statements:
Anyway, including a name for each parameter always improves legibility of the declaration.
Please, enter number (0 to exit): 9
It is odd.
Please, enter number (0 to exit): 6
It is even.
Please, enter number (0 to exit): 1030
It is even.
Please, enter number (0 to exit): 0
It is even.
This example is indeed not an example of efficiency. You can probably write yourself a version of this program with half the lines of code. Anyway, this example illustrates how functions can be declared before its definition:
The following lines:
Declare the prototype of the functions. They already contain all what is necessary to call them, their name, the types of their argument, and their return type (void in this case). With these prototype declarations in place, they can be called before they are entirely defined, allowing for example, to place the function from where they are called (main) before the actual definition of these functions.
But declaring functions before being defined is not only useful to reorganize the order of functions within the code. In some cases, such as in this particular case, at least one of the declarations is required, because odd and even are mutually called; there is a call to even in odd and a call to odd in even. And, therefore, there is no way to structure the code so that odd is defined before even, and even before odd.
Recursivity
Recursivity is the property that functions have to be called by themselves. It is useful for some tasks, such as sorting elements, or calculating the factorial of numbers. For example, in order to obtain the factorial of a number (n!) the mathematical formula would be:
n! = n * (n-1) * (n-2) * (n-3) ... * 1
More concretely, 5! (factorial of 5) would be:
5! = 5 * 4 * 3 * 2 * 1 = 120
And a recursive function to calculate this in C++ could be:
Notice how in function factorial we included a call to itself, but only if the argument passed was greater than 1, since, otherwise, the function would perform an infinite recursive loop, in which once it arrived to 0, it would continue multiplying by all the negative numbers (probably provoking a stack overflow at some point during runtime).
8 - C++ OVERLOADS AND TEMPLATES
Overloaded functions
In C++, two different functions can have the same name if their parameters are different; either because they have a different number of parameters, or because any of their parameters are of a different type. For example:
In this example, there are two functions called operate, but one of them has two parameters of type int, while the other has them of type double. The compiler knows which one to call in each case by examining the types passed as arguments when the function is called. If it is called with two int arguments, it calls to the function that has two int parameters, and if it is called with two doubles, it calls the one with two doubles.
In this example, both functions have quite different behaviors, the int version multiplies its arguments, while the double version divides them. This is generally not a good idea. Two functions with the same name are generally expected to have -at least- a similar behavior, but this example demonstrates that is entirely possible for them not to. Two overloaded functions (i.e., two functions with the same name) have entirely different definitions; they are, for all purposes, different functions, that only happen to have the same name.
Note that a function cannot be overloaded only by its return type. At least one of its parameters must have a different type.
Function templates
Overloaded functions may have the same definition. For example:
Here, sum is overloaded with different parameter types, but with the exact same body.
The function sum could be overloaded for a lot of types, and it could make sense for all of them to have the same body. For cases such as this, C++ has the ability to define functions with generic types, known as function templates. Defining a function template follows the same syntax as a regular function, except that it is preceded by the template keyword and a series of template parameters enclosed in angle-brackets <>:<br>
template <template-parameters> function-declaration
The template parameters are a series of parameters separated by commas. These parameters can be generic template types by specifying either the class or typename keyword followed by an identifier. This identifier can then be used in the function declaration as if it was a regular type. For example, a generic sum function could be defined as:
It makes no difference whether the generic type is specified with keyword class or keyword typename in the template argument list (they are 100% synonyms in template declarations).
In the code above, declaring SomeType (a generic type within the template parameters enclosed in angle-brackets) allows SomeType to be used anywhere in the function definition, just as any other type; it can be used as the type for parameters, as return type, or to declare new variables of this type. In all cases, it represents a generic type that will be determined on the moment the template is instantiated.
Instantiating a template is applying the template to create a function using particular types or values for its template parameters. This is done by calling the function template, with the same syntax as calling a regular function, but specifying the template arguments enclosed in angle brackets:
name <template-arguments> (function-arguments)
For example, the sum function template defined above can be called with:
x = sum<int>(10,20);
The function sum<int> is just one of the possible instantiations of function template sum. In this case, by using int as template argument in the call, the compiler automatically instantiates a version of sum where each occurrence of SomeType is replaced by int, as if it was defined as:
Let's see an actual example:
In this case, we have used T as the template parameter name, instead of SomeType. It makes no difference, and T is actually a quite common template parameter name for generic types.
In the example above, we used the function template sum twice. The first time with arguments of type int, and the second one with arguments of type double. The compiler has instantiated and then called each time the appropriate version of the function.
Note also how T is also used to declare a local variable of that (generic) type within sum:
T result;
Therefore, result will be a variable of the same type as the parameters a and b, and as the type returned by the function. In this specific case where the generic type T is used as a parameter for sum, the compiler is even able to deduce the data type automatically without having to explicitly specify it within angle brackets. Therefore, instead of explicitly specifying the template arguments with:
It is possible to instead simply write:
without the type enclosed in angle brackets. Naturally, for that, the type shall be unambiguous. If sum is called with arguments of different types, the compiler may not be able to deduce the type of T automatically.
Templates are a powerful and versatile feature. They can have multiple template parameters, and the function can still use regular non-templated types. For example:
Note that this example uses automatic template parameter deduction in the call to are_equal:
are_equal(10,10.0)
Is equivalent to:
are_equal<int,double>(10,10.0)
There is no ambiguity possible because numerical literals are always of a specific type: Unless otherwise specified with a suffix, integer literals always produce values of type int, and floating-point literals always produce values of type double. Therefore 10 has always type int and 10.0 has always type double.
Non-type template arguments
The template parameters can not only include types introduced by class or typename, but can also include expressions of a particular type:
20
30
The second argument of the fixed_multiply function template is of type int. It just looks like a regular function parameter, and can actually be used just like one.
But there exists a major difference: the value of template parameters is determined on compile-time to generate a different instantiation of the function fixed_multiply, and thus the value of that argument is never passed during runtime: The two calls to fixed_multiply in main essentially call two versions of the function: one that always multiplies by two, and one that always multiplies by three. For that same reason, the second template argument needs to be a constant expression (it cannot be passed a variable).
9 - C++ NAME VISIBILITY
Scopes
Named entities, such as variables, functions, and compound types need to be declared before being used in C++. The point in the program where this declaration happens influences its visibility:
An entity declared outside any block has global scope, meaning that its name is valid anywhere in the code. While an entity declared within a block, such as a function or a selective statement, has block scope, and is only visible within the specific block in which it is declared, but not outside it.
Variables with block scope are known as local variables.
For example, a variable declared in the body of a function is a local variable that extends until the end of the the function (i.e., until the brace } that closes the function definition), but not outside it:
In each scope, a name can only represent one entity. For example, there cannot be two variables with the same name in the same scope:
The visibility of an entity with block scope extends until the end of the block, including inner blocks. Nevertheless, an inner block, because it is a different block, can re-utilize a name existing in an outer scope to refer to a different entity; in this case, the name will refer to a different entity only within the inner block, hiding the entity it names outside. While outside it, it will still refer to the original entity. For example:
Note that y is not hidden in the inner block, and thus accessing y still accesses the outer variable.
Variables declared in declarations that introduce a block, such as function parameters and variables declared in loops and conditions (such as those declared on a for or an if) are local to the block they introduce.
Namespaces
Only one entity can exist with a particular name in a particular scope. This is seldom a problem for local names, since blocks tend to be relatively short, and names have particular purposes within them, such as naming a counter variable, an argument, etc...
But non-local names bring more possibilities for name collision, especially considering that libraries may declare many functions, types, and variables, neither of them local in nature, and some of them very generic.
Namespaces allow us to group named entities that otherwise would have global scope into narrower scopes, giving them namespace scope. This allows organizing the elements of programs into different logical scopes referred to by names.
The syntax to declare a namespaces is:
Where identifier is any valid identifier and named_entities is the set of variables, types and functions that are included within the namespace. For example:
In this case, the variables a and b are normal variables declared within a namespace called myNamespace.
These variables can be accessed from within their namespace normally, with their identifier (either a or b), but if accessed from outside the myNamespace namespace they have to be properly qualified with the scope operator ::. For example, to access the previous variables from outside myNamespace they should be qualified like:
Namespaces are particularly useful to avoid name collisions. For example:
5
6.2832
3.1416
In this case, there are two functions with the same name: value. One is defined within the namespace foo, and the other one in bar. No redefinition errors happen thanks to namespaces. Notice also how pi is accessed in an unqualified manner from within namespace bar (just as pi), while it is again accessed in main, but here it needs to be qualified as bar::pi.
Namespaces can be split: Two segments of a code can be declared in the same namespace:
This declares three variables: a and c are in namespace foo, while b is in namespace bar. Namespaces can even extend across different translation units (i.e., across different files of source code).
using
The keyword using introduces a name into the current declarative region (such as a block), thus avoiding the need to qualify the name. For example:
5
2.7183
10
3.1416
Notice how in main, the variable x (without any name qualifier) refers to first::x, whereas y refers to second::y, just as specified by the using declarations. The variables first::y and second::x can still be accessed, but require fully qualified names.
The keyword using can also be used as a directive to introduce an entire namespace:
5
10
3.1416
2.7183
In this case, by declaring that we were using namespace first, all direct uses of x and y without name qualifiers were also looked up in namespace first.
using and using namespace have validity only in the same block in which they are stated or in the entire source code file if they are used directly in the global scope. For example, it would be possible to first use the objects of one namespace and then those of another one by splitting the code in different blocks:
5
3.1416
Namespace aliasing
Existing namespaces can be aliased with new names, with the following syntax:
namespace new_name = current_name;
The std namespace
All the entities (variables, types, constants, and functions) of the standard C++ library are declared within the std namespace. Most examples in these tutorials, in fact, include the following line:
using namespace std;
This introduces direct visibility of all the names of the std namespace into the code. This is done in these tutorials to facilitate comprehension and shorten the length of the examples, but many programmers prefer to qualify each of the elements of the standard library used in their programs. For example, instead of:
cout << "Hello world!";
It is common to instead see:
std::cout << "Hello world!";
Whether the elements in the std namespace are introduced with using declarations or are fully qualified on every use does not change the behavior or efficiency of the resulting program in any way. It is mostly a matter of style preference, although for projects mixing libraries, explicit qualification tends to be preferred.
Whether the elements in the std namespace are introduced with using declarations or are fully qualified on every use does not change the behavior or efficiency of the resulting program in any way. It is mostly a matter of style preference, although for projects mixing libraries, explicit qualification tends to be preferred.
Storage classes
The storage for variables with global or namespace scope is allocated for the entire duration of the program. This is known as static storage, and it contrasts with the storage for local variables (those declared within a block). These use what is known as automatic storage. The storage for local variables is only available during the block in which they are declared; after that, that same storage may be used for a local variable of some other function, or used otherwise.
But there is another substantial difference between variables with static storage and variables with automatic storage:
- Variables with static storage (such as global variables) that are not explicitly initialized are automatically initialized to zeroes.
- Variables with automatic storage (such as local variables) that are not explicitly initialized are left uninitialized, and thus have an undetermined value.
For example:
0
4285838
The actual output may vary, but only the value of x is guaranteed to be zero. y can actually contain just about any value (including zero).
10 - C++ ARRAYS
An array is a series of elements of the same type placed in contiguous memory locations that can be individually referenced by adding an index to a unique identifier.
That means that, for example, five values of type int can be declared as an array without having to declare 5 different variables (each with its own identifier). Instead, using an array, the five int values are stored in contiguous memory locations, and all five can be accessed using the same identifier, with the proper index.
For example, an array containing 5 integer values of type int called foo could be represented as:

where each blank panel represents an element of the array. In this case, these are values of type int. These elements are numbered from 0 to 4, being 0 the first and 4 the last; In C++, the first element in an array is always numbered with a zero (not a one), no matter its length.
Like a regular variable, an array must be declared before it is used. A typical declaration for an array in C++ is:
type name [elements];
where type is a valid type (such as int, float...), name is a valid identifier and the elements field (which is always enclosed in square brackets []), specifies the length of the array in terms of the number of elements.
Therefore, the foo array, with five elements of type int, can be declared as:
int foo [5];
NOTE: The elements field within square brackets [], representing the number of elements in the array, must be a constant expression, since arrays are blocks of static memory whose size must be determined at compile time, before the program runs.
Initializing arrays
By default, regular arrays of local scope (for example, those declared within a function) are left uninitialized. This means that none of its elements are set to any particular value; their contents are undetermined at the point the array is declared.
But the elements in an array can be explicitly initialized to specific values when it is declared, by enclosing those initial values in braces {}. For example:
int foo [5] = { 16, 2, 77, 40, 12071 };
This statement declares an array that can be represented like this:

The number of values between braces {} shall not be greater than the number of elements in the array. For example, in the example above, foo was declared having 5 elements (as specified by the number enclosed in square brackets, []), and the braces {} contained exactly 5 values, one for each element. If declared with less, the remaining elements are set to their default values (which for fundamental types, means they are filled with zeroes). For example:
int bar [5] = { 10, 20, 30 };
Will create an array like this:

The initializer can even have no values, just the braces:
int baz [5] = { };
This creates an array of five int values, each initialized with a value of zero:

When an initialization of values is provided for an array, C++ allows the possibility of leaving the square brackets empty []. In this case, the compiler will assume automatically a size for the array that matches the number of values included between the braces {}:
int foo [] = { 16, 2, 77, 40, 12071 };
After this declaration, array foo would be 5 int long, since we have provided 5 initialization values.
Finally, the evolution of C++ has led to the adoption of universal initialization also for arrays. Therefore, there is no longer need for the equal sign between the declaration and the initializer. Both these statements are equivalent:
int foo[] = { 10, 20, 30 };
int foo[] { 10, 20, 30 };
Static arrays, and those declared directly in a namespace (outside any function), are always initialized. If no explicit initializer is specified, all the elements are default-initialized (with zeroes, for fundamental types).
Accessing the values of an array
The values of any of the elements in an array can be accessed just like the value of a regular variable of the same type. The syntax is:
name[index]
Following the previous examples in which foo had 5 elements and each of those elements was of type int, the name which can be used to refer to each element is the following:

For example, the following statement stores the value 75 in the third element of foo:
foo [2] = 75;
and, for example, the following copies the value of the third element of foo to a variable called x:
x = foo[2];
Therefore, the expression foo[2] is itself a variable of type int.
Notice that the third element of foo is specified foo[2], since the first one is foo[0], the second one is foo[1], and therefore, the third one is foo[2]. By this same reason, its last element is foo[4]. Therefore, if we write foo[5], we would be accessing the sixth element of foo, and therefore actually exceeding the size of the array.
In C++, it is syntactically correct to exceed the valid range of indices for an array. This can create problems, since accessing out-of-range elements do not cause errors on compilation, but can cause errors on runtime. The reason for this being allowed will be seen in a later chapter when pointers are introduced.
At this point, it is important to be able to clearly distinguish between the two uses that brackets [] have related to arrays. They perform two different tasks: one is to specify the size of arrays when they are declared; and the second one is to specify indices for concrete array elements when they are accessed. Do not confuse these two possible uses of brackets [] with arrays.
12206
Multidimensional arrays
Multidimensional arrays can be described as "arrays of arrays". For example, a bidimensional array can be imagined as a two-dimensional table made of elements, all of them of a same uniform data type.

jimmy represents a bidimensional array of 3 per 5 elements of type int. The C++ syntax for this is:
int jimmy [3][5];
and, for example, the way to reference the second element vertically and fourth horizontally in an expression would be:
jimmy[1][3]
(remember that array indices always begin with zero).
Multidimensional arrays are not limited to two indices (i.e., two dimensions). They can contain as many indices as needed. Although be careful: the amount of memory needed for an array increases exponentially with each dimension. For example:
char century [100][365][24][60][60];
declares an array with an element of type char for each second in a century. This amounts to more than 3 billion char! So this declaration would consume more than 3 gigabytes of memory!
At the end, multidimensional arrays are just an abstraction for programmers, since the same results can be achieved with a simple array, by multiplying its indices:
int jimmy [3][5]; // is equivalent to
int jimmy [15]; // (3 * 5 = 15)
With the only difference that with multidimensional arrays, the compiler automatically remembers the depth of each imaginary dimension. The following two pieces of code produce the exact same result, but one uses a bidimensional array while the other uses a simple array:
| multidimensional array | pseudo-multidimensional array |
|---|---|
|
|
None of the two code snippets above produce any output on the screen, but both assign values to the memory block called jimmy in the following way:

Note that the code uses defined constants for the width and height, instead of using directly their numerical values. This gives the code a better readability, and allows changes in the code to be made easily in one place.
Arrays as parameters
At some point, we may need to pass an array to a function as a parameter. In C++, it is not possible to pass the entire block of memory represented by an array to a function directly as an argument. But what can be passed instead is its address. In practice, this has almost the same effect, and it is a much faster and more efficient operation.
To accept an array as parameter for a function, the parameters can be declared as the array type, but with empty brackets, omitting the actual size of the array. For example:
void procedure (int arg[])
This function accepts a parameter of type "array of int" called arg. In order to pass to this function an array declared as:
int myarray [40];
it would be enough to write a call like this:
procedure (myarray);
Here you have a complete example:
5 10 15
2 4 6 8 10
In the code above, the first parameter (int arg[]) accepts any array whose elements are of type int, whatever its length. For that reason, we have included a second parameter that tells the function the length of each array that we pass to it as its first parameter. This allows the for loop that prints out the array to know the range to iterate in the array passed, without going out of range.
In a function declaration, it is also possible to include multidimensional arrays. The format for a tridimensional array parameter is:
base_type[][depth][depth]
For example, a function with a multidimensional array as argument could be:
void procedure (int myarray[][3][4])
Notice that the first brackets [] are left empty, while the following ones specify sizes for their respective dimensions. This is necessary in order for the compiler to be able to determine the depth of each additional dimension.
In a way, passing an array as argument always loses a dimension. The reason behind is that, for historical reasons, arrays cannot be directly copied, and thus what is really passed is a pointer. This is a common source of errors for novice programmers. Although a clear understanding of pointers, explained in a coming chapter, helps a lot.
Library arrays
The arrays explained above are directly implemented as a language feature, inherited from the C language. They are a great feature, but by restricting its copy and easily decay into pointers, they probably suffer from an excess of optimization.
To overcome some of these issues with language built-in arrays, C++ provides an alternative array type as a standard container. It is a type template (a class template, in fact) defined in header <array>.
Containers are a library feature that falls out of the scope of this tutorial, and thus the class will not be explained in detail here. Suffice it to say that they operate in a similar way to built-in arrays, except that they allow being copied (an actually expensive operation that copies the entire block of memory, and thus to use with care) and decay into pointers only when explicitly told to do so (by means of its member data).
Just as an example, these are two versions of the same example using the language built-in array described in this chapter, and the container in the library:
| language built-in array | container library array |
|---|---|
|
|
As you can see, both kinds of arrays use the same syntax to access its elements: myarray[i]. Other than that, the main differences lay on the declaration of the array, and the inclusion of an additional header for the library array. Notice also how it is easy to access the size of the library array.
11 - C++ CHARACTER SWQUENCES
The string class has been briefly introduced in an earlier chapter. It is a very powerful class to handle and manipulate strings of characters. However, because strings are, in fact, sequences of characters, we can represent them also as plain arrays of elements of a character type.
For example, the following array:
char foo [20];
is an array that can store up to 20 elements of type char. It can be represented as:

Therefore, this array has a capacity to store sequences of up to 20 characters. But this capacity does not need to be fully exhausted: the array can also accommodate shorter sequences. For example, at some point in a program, either the sequence "Hello" or the sequence "Merry Christmas" can be stored in foo, since both would fit in a sequence with a capacity for 20 characters.
By convention, the end of strings represented in character sequences is signaled by a special character: the null character, whose literal value can be written as '\0' (backslash, zero).
In this case, the array of 20 elements of type char called foo can be represented storing the character sequences "Hello" and "Merry Christmas" as:

Notice how after the content of the string itself, a null character ('\0') has been added in order to indicate the end of the sequence. The panels in gray color represent char elements with undetermined values.
Initialization of null-terminated character sequences
Because arrays of characters are ordinary arrays, they follow the same rules as these. For example, to initialize an array of characters with some predetermined sequence of characters, we can do it just like any other array:
char myword[] = { 'H', 'e', 'l', 'l', 'o', '\0' };
The above declares an array of 6 elements of type char initialized with the characters that form the word "Hello" plus a null character '\0' at the end.
But arrays of character elements have another way to be initialized: using string literals directly.
In the expressions used in some examples in previous chapters, string literals have already shown up several times. These are specified by enclosing the text between double quotes ("). For example:
"the result is: " This is a string literal, probably used in some earlier example.
Sequences of characters enclosed in double-quotes (") are literal constants. And their type is, in fact, a null-terminated array of characters. This means that string literals always have a null character ('\0') automatically appended at the end.
Therefore, the array of char elements called myword can be initialized with a null-terminated sequence of characters by either one of these two statements:
char myword[] = { 'H', 'e', 'l', 'l', 'o', '\0' };
char myword[] = "Hello";
In both cases, the array of characters myword is declared with a size of 6 elements of type char: the 5 characters that compose the word "Hello", plus a final null character ('\0'), which specifies the end of the sequence and that, in the second case, when using double quotes (") it is appended automatically.
Please notice that here we are talking about initializing an array of characters at the moment it is being declared, and not about assigning values to them later (once they have already been declared). In fact, because string literals are regular arrays, they have the same restrictions as these, and cannot be assigned values.
Expressions (once myword has already been declared as above), such as:
myword = "Bye";
myword[] = "Bye";
would not be valid, like neither would be:
myword = { 'B', 'y', 'e', '\0' };
This is because arrays cannot be assigned values. Note, though, that each of its elements can be assigned a value individually. For example, this would be correct:
myword[0] = 'B';
myword[1] = 'y';
myword[2] = 'e';
myword[3] = '\0';
Strings and null-terminated character sequences
Plain arrays with null-terminated sequences of characters are the typical types used in the C language to represent strings (that is why they are also known as C-strings). In C++, even though the standard library defines a specific type for strings (class string), still, plain arrays with null-terminated sequences of characters (C-strings) are a natural way of representing strings in the language; in fact, string literals still always produce null-terminated character sequences, and not string objects.
In the standard library, both representations for strings (C-strings and library strings) coexist, and most functions requiring strings are overloaded to support both.
For example, cin and cout support null-terminated sequences directly, allowing them to be directly extracted from cin or inserted into cout, just like strings. For example:
What is your name? Homer
Where do you live? Greece
Hello, Homer from Greece!
In this example, both arrays of characters using null-terminated sequences and strings are used. They are quite interchangeable in their use together with cin and cout, but there is a notable difference in their declarations: arrays have a fixed size that needs to be specified either implicit or explicitly when declared; question1 has a size of exactly 20 characters (including the terminating null-characters) and answer1 has a size of 80 characters; while strings are simply strings, no size is specified. This is due to the fact that strings have a dynamic size determined during runtime, while the size of arrays is determined on compilation, before the program runs.
In any case, null-terminated character sequences and strings are easily transformed from one another:
Null-terminated character sequences can be transformed into strings implicitly, and strings can be transformed into null-terminated character sequences by using either of string's member functions c_str or data:
12 - C++ POINTERS
In earlier chapters, variables have been explained as locations in the computer's memory which can be accessed by their identifier (their name). This way, the program does not need to care about the physical address of the data in memory; it simply uses the identifier whenever it needs to refer to the variable.
For a C++ program, the memory of a computer is like a succession of memory cells, each one byte in size, and each with a unique address. These single-byte memory cells are ordered in a way that allows data representations larger than one byte to occupy memory cells that have consecutive addresses.
This way, each cell can be easily located in the memory by means of its unique address. For example, the memory cell with the address 1776 always follows immediately after the cell with address 1775 and precedes the one with 1777, and is exactly one thousand cells after 776 and exactly one thousand cells before 2776.
When a variable is declared, the memory needed to store its value is assigned a specific location in memory (its memory address). Generally, C++ programs do not actively decide the exact memory addresses where its variables are stored. Fortunately, that task is left to the environment where the program is run - generally, an operating system that decides the particular memory locations on runtime. However, it may be useful for a program to be able to obtain the address of a variable during runtime in order to access data cells that are at a certain position relative to it.
Address-of operator (&)
The address of a variable can be obtained by preceding the name of a variable with an ampersand sign (&), known as address-of operator. For example:
foo = &myvar;
This would assign the address of variable myvar to foo; by preceding the name of the variable myvar with the address-of operator (&), we are no longer assigning the content of the variable itself to foo, but its address.
The actual address of a variable in memory cannot be known before runtime, but let's assume, in order to help clarify some concepts, that myvar is placed during runtime in the memory address 1776.
In this case, consider the following code fragment:
myvar = 25;
foo = &myvar;
bar = myvar;
The values contained in each variable after the execution of this are shown in the following diagram:
First, we have assigned the value 25 to myvar (a variable whose address in memory we assumed to be 1776).
The second statement assigns foo the address of myvar, which we have assumed to be 1776.
Finally, the third statement, assigns the value contained in myvar to bar. This is a standard assignment operation, as already done many times in earlier chapters.
The main difference between the second and third statements is the appearance of the address-of operator (&).
The variable that stores the address of another variable (like foo in the previous example) is what in C++ is called a pointer. Pointers are a very powerful feature of the language that has many uses in lower level programming. A bit later, we will see how to declare and use pointers.
Dereference operator (*)
As just seen, a variable which stores the address of another variable is called a pointer. Pointers are said to "point to" the variable whose address they store.
An interesting property of pointers is that they can be used to access the variable they point to directly. This is done by preceding the pointer name with the dereference operator (*). The operator itself can be read as "value pointed to by".
Therefore, following with the values of the previous example, the following statement:
baz = *foo;
This could be read as: "baz equal to value pointed to by foo", and the statement would actually assign the value 25 to baz, since foo is 1776, and the value pointed to by 1776 (following the example above) would be 25.
It is important to clearly differentiate that foo refers to the value 1776, while *foo (with an asterisk * preceding the identifier) refers to the value stored at address 1776, which in this case is 25. Notice the difference of including or not including the dereference operator (I have added an explanatory comment of how each of these two expressions could be read):
The reference and dereference operators are thus complementary:
- & is the address-of operator, and can be read simply as "address of"
- * is the dereference operator, and can be read as "value pointed to by"
Thus, they have sort of opposite meanings: An address obtained with & can be dereferenced with *.
Earlier, we performed the following two assignment operations:
myvar = 25;
foo = &myvar;
Right after these two statements, all of the following expressions would give true as result:
myvar == 25
&myvar == 1776
foo == 1776
*foo == 25
The first expression is quite clear, considering that the assignment operation performed on myvar was myvar=25. The second one uses the address-of operator (&), which returns the address of myvar, which we assumed it to have a value of 1776. The third one is somewhat obvious, since the second expression was true and the assignment operation performed on foo was foo=&myvar. The fourth expression uses the dereference operator (*) that can be read as "value pointed to by", and the value pointed to by foo is indeed 25.
So, after all that, you may also infer that for as long as the address pointed to by foo remains unchanged, the following expression will also be true:
*foo == myvar
Declaring pointers
Due to the ability of a pointer to directly refer to the value that it points to, a pointer has different properties when it points to a char than when it points to an int or a float. Once dereferenced, the type needs to be known. And for that, the declaration of a pointer needs to include the data type the pointer is going to point to.
The declaration of pointers follows this syntax:
type * name;
where type is the data type pointed to by the pointer. This type is not the type of the pointer itself, but the type of the data the pointer points to. For example:
int * number;
char * character;
double * decimals;
These are three declarations of pointers. Each one is intended to point to a different data type, but, in fact, all of them are pointers and all of them are likely going to occupy the same amount of space in memory (the size in memory of a pointer depends on the platform where the program runs). Nevertheless, the data to which they point to do not occupy the same amount of space nor are of the same type: the first one points to an int, the second one to a char, and the last one to a double. Therefore, although these three example variables are all of them pointers, they actually have different types: int*, char*, and double* respectively, depending on the type they point to.
Note that the asterisk (*) used when declaring a pointer only means that it is a pointer (it is part of its type compound specifier), and should not be confused with the dereference operator seen a bit earlier, but which is also written with an asterisk (*). They are simply two different things represented with the same sign.
Let's see an example on pointers:
firstvalue is 10
secondvalue is 20
Notice that even though neither firstvalue nor secondvalue are directly set any value in the program, both end up with a value set indirectly through the use of mypointer. This is how it happens:
First, mypointer is assigned the address of firstvalue using the address-of operator (&). Then, the value pointed to by mypointer is assigned a value of 10. Because, at this moment, mypointer is pointing to the memory location of firstvalue, this in fact modifies the value of firstvalue.
In order to demonstrate that a pointer may point to different variables during its lifetime in a program, the example repeats the process with secondvalue and that same pointer, mypointer.
Here is an example a little bit more elaborated:
firstvalue is 10
secondvalue is 20
Each assignment operation includes a comment on how each line could be read: i.e., replacing ampersands (&) by "address of", and asterisks (*) by "value pointed to by".
Notice that there are expressions with pointers p1 and p2, both with and without the dereference operator (*). The meaning of an expression using the dereference operator (*) is very different from one that does not. When this operator precedes the pointer name, the expression refers to the value being pointed, while when a pointer name appears without this operator, it refers to the value of the pointer itself (i.e., the address of what the pointer is pointing to).
Another thing that may call your attention is the line:
int * p1, * p2;
This declares the two pointers used in the previous example. But notice that there is an asterisk (*) for each pointer, in order for both to have type int* (pointer to int). This is required due to the precedence rules. Note that if, instead, the code was:
int * p1, p2;
p1 would indeed be of type int*, but p2 would be of type int. Spaces do not matter at all for this purpose. But anyway, simply remembering to put one asterisk per pointer is enough for most pointer users interested in declaring multiple pointers per statement. Or even better: use a different statemet for each variable.
Pointers and arrays
The concept of arrays is related to that of pointers. In fact, arrays work very much like pointers to their first elements, and, actually, an array can always be implicitly converted to the pointer of the proper type. For example, consider these two declarations:
int myarray [20];
int * mypointer;
The following assignment operation would be valid:
mypointer = myarray;
After that, mypointer and myarray would be equivalent and would have very similar properties. The main difference being that mypointer can be assigned a different address, whereas myarray can never be assigned anything, and will always represent the same block of 20 elements of type int. Therefore, the following assignment would not be valid:
myarray = mypointer;
Let's see an example that mixes arrays and pointers:
10, 20, 30, 40, 50,
Pointers and arrays support the same set of operations, with the same meaning for both. The main difference being that pointers can be assigned new addresses, while arrays cannot.
In the chapter about arrays, brackets ([]) were explained as specifying the index of an element of the array. Well, in fact these brackets are a dereferencing operator known as offset operator. They dereference the variable they follow just as * does, but they also add the number between brackets to the address being dereferenced. For example:
a[5] = 0; // a [offset of 5] = 0
*(a+5) = 0; // pointed to by (a+5) = 0
<p.These two expressions are equivalent and valid, not only if a is a pointer, but also if a is an array. Remember that if an array, its name can be used just like a pointer to its first element.
Pointer initialization
Pointers can be initialized to point to specific locations at the very moment they are defined:
int myvar;
int * myptr = &myvar;
The resulting state of variables after this code is the same as after:
int myvar;
int * myptr;
myptr = &myvar;
When pointers are initialized, what is initialized is the address they point to (i.e., myptr), never the value being pointed (i.e., *myptr). Therefore, the code above shall not be confused with:
int myvar;
int * myptr;
*myptr = &myvar;
Which anyway would not make much sense (and is not valid code).
The asterisk (*) in the pointer declaration (line 2) only indicates that it is a pointer, it is not the dereference operator (as in line 3). Both things just happen to use the same sign: *. As always, spaces are not relevant, and never change the meaning of an expression.
Pointers can be initialized either to the address of a variable (such as in the case above), or to the value of another pointer (or array):
int myvar;
int *foo = &myvar;
int *bar = foo;
Pointer arithmetics
To conduct arithmetical operations on pointers is a little different than to conduct them on regular integer types. To begin with, only addition and subtraction operations are allowed; the others make no sense in the world of pointers. But both addition and subtraction have a slightly different behavior with pointers, according to the size of the data type to which they point.
When fundamental data types were introduced, we saw that types have different sizes. For example: char always has a size of 1 byte, short is generally larger than that, and int and long are even larger; the exact size of these being dependent on the system. For example, let's imagine that in a given system, char takes 1 byte, short takes 2 bytes, and long takes 4.
Suppose now that we define three pointers in this compiler:
char *mychar;
short *myshort;
long *mylong;
and that we know that they point to the memory locations 1000, 2000, and 3000, respectively.
Therefore, if we write:
++mychar;
++myshort;
++mylong;
mychar, as one would expect, would contain the value 1001. But not so obviously, myshort would contain the value 2002, and mylong would contain 3004, even though they have each been incremented only once. The reason is that, when adding one to a pointer, the pointer is made to point to the following element of the same type, and, therefore, the size in bytes of the type it points to is added to the pointer.
This is applicable both when adding and subtracting any number to a pointer. It would happen exactly the same if we wrote:
mychar = mychar + 1;
myshort = myshort + 1;
mylong = mylong + 1;
Regarding the increment (++) and decrement (--) operators, they both can be used as either prefix or suffix of an expression, with a slight difference in behavior: as a prefix, the increment happens before the expression is evaluated, and as a suffix, the increment happens after the expression is evaluated. This also applies to expressions incrementing and decrementing pointers, which can become part of more complicated expressions that also include dereference operators (*). Remembering operator precedence rules, we can recall that postfix operators, such as increment and decrement, have higher precedence than prefix operators, such as the dereference operator (*). Therefore, the following expression:
*p++
is equivalent to *(p++). And what it does is to increase the value of p (so it now points to the next element), but because ++ is used as postfix, the whole expression is evaluated as the value pointed originally by the pointer (the address it pointed to before being incremented).
Essentially, these are the four possible combinations of the dereference operator with both the prefix and suffix versions of the increment operator (the same being applicable also to the decrement operator):
A typical -but not so simple- statement involving these operators is:
*p++ = *q++;
Because ++ has a higher precedence than *, both p and q are incremented, but because both increment operators (++) are used as postfix and not prefix, the value assigned to *p is *q before both p and q are incremented. And then both are incremented. It would be roughly equivalent to:
*p = *q;
++p;
++q;
Like always, parentheses reduce confusion by adding legibility to expressions.
Pointers and const
Pointers can be used to access a variable by its address, and this access may include modifying the value pointed. But it is also possible to declare pointers that can access the pointed value to read it, but not to modify it. For this, it is enough with qualifying the type pointed to by the pointer as const. For example:
Here p points to a variable, but points to it in a const-qualified manner, meaning that it can read the value pointed, but it cannot modify it. Note also, that the expression &y is of type int*, but this is assigned to a pointer of type const int*. This is allowed: a pointer to non-const can be implicitly converted to a pointer to const. But not the other way around! As a safety feature, pointers to const are not implicitly convertible to pointers to non-const.
One of the use cases of pointers to const elements is as function parameters: a function that takes a pointer to non-const as parameter can modify the value passed as argument, while a function that takes a pointer to const as parameter cannot.
11
21
31
Note that print_all uses pointers that point to constant elements. These pointers point to constant content they cannot modify, but they are not constant themselves: i.e., the pointers can still be incremented or assigned different addresses, although they cannot modify the content they point to.
And this is where a second dimension to constness is added to pointers: Pointers can also be themselves const. And this is specified by appending const to the pointed type (after the asterisk):
The syntax with const and pointers is definitely tricky, and recognizing the cases that best suit each use tends to require some experience. In any case, it is important to get constness with pointers (and references) right sooner rather than later, but you should not worry too much about grasping everything if this is the first time you are exposed to the mix of const and pointers. More use cases will show up in coming chapters.
To add a little bit more confusion to the syntax of const with pointers, the const qualifier can either precede or follow the pointed type, with the exact same meaning:
As with the spaces surrounding the asterisk, the order of const in this case is simply a matter of style. This chapter uses a prefix const, as for historical reasons this seems to be more extended, but both are exactly equivalent. The merits of each style are still intensely debated on the internet.
Pointers and string literals
As pointed earlier, string literals are arrays containing null-terminated character sequences. In earlier sections, string literals have been used to be directly inserted into cout, to initialize strings and to initialize arrays of characters.
But they can also be accessed directly. String literals are arrays of the proper array type to contain all its characters plus the terminating null-character, with each of the elements being of type const char (as literals, they can never be modified). For example:
const char * foo = "hello";
This declares an array with the literal representation for "hello", and then a pointer to its first element is assigned to foo. If we imagine that "hello" is stored at the memory locations that start at address 1702, we can represent the previous declaration as:
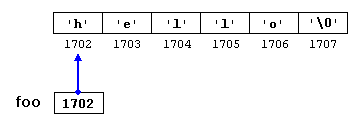
Note that here foo is a pointer and contains the value 1702, and not 'h', nor "hello", although 1702 indeed is the address of both of these.
The pointer foo points to a sequence of characters. And because pointers and arrays behave essentially in the same way in expressions, foo can be used to access the characters in the same way arrays of null-terminated character sequences are. For example:
*(foo+4)
foo[4]
Both expressions have a value of 'o' (the fifth element of the array).
Pointers to pointers
C++ allows the use of pointers that point to pointers, that these, in its turn, point to data (or even to other pointers). The syntax simply requires an asterisk (*) for each level of indirection in the declaration of the pointer:
This, assuming the randomly chosen memory locations for each variable of 7230, 8092, and 10502, could be represented as:
With the value of each variable represented inside its corresponding cell, and their respective addresses in memory represented by the value under them.
The new thing in this example is variable c, which is a pointer to a pointer, and can be used in three different levels of indirection, each one of them would correspond to a different value:
- c is of type char** and a value of 8092
- *c is of type char* and a value of 7230
- **c is of type char and a value of 'z'
void pointers
The void type of pointer is a special type of pointer. In C++, void represents the absence of type. Therefore, void pointers are pointers that point to a value that has no type (and thus also an undetermined length and undetermined dereferencing properties).
This gives void pointers a great flexibility, by being able to point to any data type, from an integer value or a float to a string of characters. In exchange, they have a great limitation: the data pointed to by them cannot be directly dereferenced (which is logical, since we have no type to dereference to), and for that reason, any address in a void pointer needs to be transformed into some other pointer type that points to a concrete data type before being dereferenced.
One of its possible uses may be to pass generic parameters to a function. For example:
y, 1603
sizeof is an operator integrated in the C++ language that returns the size in bytes of its argument. For non-dynamic data types, this value is a constant. Therefore, for example, sizeof(char) is 1, because char has always a size of one byte.
Invalid pointers and null pointers
In principle, pointers are meant to point to valid addresses, such as the address of a variable or the address of an element in an array. But pointers can actually point to any address, including addresses that do not refer to any valid element. Typical examples of this are uninitialized pointers and pointers to nonexistent elements of an array:
Neither p nor q point to addresses known to contain a value, but none of the above statements causes an error. In C++, pointers are allowed to take any address value, no matter whether there actually is something at that address or not. What can cause an error is to dereference such a pointer (i.e., actually accessing the value they point to). Accessing such a pointer causes undefined behavior, ranging from an error during runtime to accessing some random value.
But, sometimes, a pointer really needs to explicitly point to nowhere, and not just an invalid address. For such cases, there exists a special value that any pointer type can take: the null pointer value. This value can be expressed in C++ in two ways: either with an integer value of zero, or with the nullptr keyword:
int * p = 0;
int * q = nullptr;
Here, both p and q are null pointers, meaning that they explicitly point to nowhere, and they both actually compare equal: all null pointers compare equal to other null pointers. It is also quite usual to see the defined constant NULL be used in older code to refer to the null pointer value:
int * r = NULL;
NULL is defined in several headers of the standard library, and is defined as an alias of some null pointer constant value (such as 0 or nullptr).
Do not confuse null pointers with void pointers! A null pointer is a value that any pointer can take to represent that it is pointing to "nowhere", while a void pointer is a type of pointer that can point to somewhere without a specific type. One refers to the value stored in the pointer, and the other to the type of data it points to.
Pointers to functions
C++ allows operations with pointers to functions. The typical use of this is for passing a function as an argument to another function. Pointers to functions are declared with the same syntax as a regular function declaration, except that the name of the function is enclosed between parentheses () and an asterisk (*) is inserted before the name:
8
In the example above, minus is a pointer to a function that has two parameters of type int. It is directly initialized to point to the function subtraction:
int (* minus)(int,int) = subtraction;
13 - C++ DYNAMIC MEMORY
In the programs seen in previous chapters, all memory needs were determined before program execution by defining the variables needed. But there may be cases where the memory needs of a program can only be determined during runtime. For example, when the memory needed depends on user input. On these cases, programs need to dynamically allocate memory, for which the C++ language integrates the operators new and delete.
Operators new and new[]
Dynamic memory is allocated using operator new. new is followed by a data type specifier and, if a sequence of more than one element is required, the number of these within brackets []. It returns a pointer to the beginning of the new block of memory allocated. Its syntax is:
pointer = new type
The first expression is used to allocate memory to contain one single element of type type. The second one is used to allocate a block (an array) of elements of type type, where number_of_elements is an integer value representing the amount of these. For example:
pointer = new type [number_of_elements]
int * foo;
foo = new int [5];
In this case, the system dynamically allocates space for five elements of type int and returns a pointer to the first element of the sequence, which is assigned to foo (a pointer). Therefore, foo now points to a valid block of memory with space for five elements of type int.
Here, foo is a pointer, and thus, the first element pointed to by foo can be accessed either with the expression foo[0] or the expression *foo (both are equivalent). The second element can be accessed either with foo[1] or *(foo+1), and so on...
There is a substantial difference between declaring a normal array and allocating dynamic memory for a block of memory using new. The most important difference is that the size of a regular array needs to be a constant expression, and thus its size has to be determined at the moment of designing the program, before it is run, whereas the dynamic memory allocation performed by new allows to assign memory during runtime using any variable value as size.
The dynamic memory requested by our program is allocated by the system from the memory heap. However, computer memory is a limited resource, and it can be exhausted. Therefore, there are no guarantees that all requests to allocate memory using operator new are going to be granted by the system.
C++ provides two standard mechanisms to check if the allocation was successful:
One is by handling exceptions. Using this method, an exception of type bad_alloc is thrown when the allocation fails. Exceptions are a powerful C++ feature explained later in these tutorials. But for now, you should know that if this exception is thrown and it is not handled by a specific handler, the program execution is terminated.
This exception method is the method used by default by new, and is the one used in a declaration like:
foo = new int [5]; // if allocation fails, an exception is thrown The other method is known as nothrow, and what happens when it is used is that when a memory allocation fails, instead of throwing a bad_alloc exception or terminating the program, the pointer returned by new is a null pointer, and the program continues its execution normally.
This method can be specified by using a special object called nothrow, declared in header <new>, as argument for new:
foo = new (nothrow) int [5];
In this case, if the allocation of this block of memory fails, the failure can be detected by checking if foo is a null pointer:
This nothrow method is likely to produce less efficient code than exceptions, since it implies explicitly checking the pointer value returned after each and every allocation. Therefore, the exception mechanism is generally preferred, at least for critical allocations. Still, most of the coming examples will use the nothrow mechanism due to its simplicity.
Operators delete and delete[]
In most cases, memory allocated dynamically is only needed during specific periods of time within a program; once it is no longer needed, it can be freed so that the memory becomes available again for other requests of dynamic memory. This is the purpose of operator delete, whose syntax is:
delete pointer;
delete[] pointer;
he first statement releases the memory of a single element allocated using new, and the second one releases the memory allocated for arrays of elements using new and a size in brackets ([]).
The value passed as argument to delete shall be either a pointer to a memory block previously allocated with new, or a null pointer (in the case of a null pointer, delete produces no effect).
How many numbers would you like to type? 5
Enter number : 75
Enter number : 436
Enter number : 1067
Enter number : 8
Enter number : 32
You have entered: 75, 436, 1067, 8, 32,
Notice how the value within brackets in the new statement is a variable value entered by the user (i), not a constant expression:
p= new (nothrow) int[i];
There always exists the possibility that the user introduces a value for i so big that the system cannot allocate enough memory for it. For example, when I tried to give a value of 1 billion to the "How many numbers" question, my system could not allocate that much memory for the program, and I got the text message we prepared for this case (Error: memory could not be allocated).
It is considered good practice for programs to always be able to handle failures to allocate memory, either by checking the pointer value (if nothrow) or by catching the proper exception.
14 - C++ DATA STRUCTURES
Data structures
A data structure is a group of data elements grouped together under one name. These data elements, known as members, can have different types and different lengths. Data structures can be declared in C++ using the following syntax:
struct type_name {
member_type1 member_name1;
member_type2 member_name2;
member_type3 member_name3;
.
.
} object_names;
Where type_name is a name for the structure type, object_name can be a set of valid identifiers for objects that have the type of this structure. Within braces {}, there is a list with the data members, each one is specified with a type and a valid identifier as its name.
For example:
This declares a structure type, called product, and defines it having two members: weight and price, each of a different fundamental type. This declaration creates a new type (product), which is then used to declare three objects (variables) of this type: apple, banana, and melon. Note how once product is declared, it is used just like any other type.
Right at the end of the struct definition, and before the ending semicolon (;), the optional field object_names can be used to directly declare objects of the structure type. For example, the structure objects apple, banana, and melon can be declared at the moment the data structure type is defined:
In this case, where object_names are specified, the type name (product) becomes optional: struct requires either a type_name or at least one name in object_names, but not necessarily both.
It is important to clearly differentiate between what is the structure type name (product), and what is an object of this type (apple, banana, and melon). Many objects (such as apple, banana, and melon) can be declared from a single structure type (product).
Once the three objects of a determined structure type are declared (apple, banana, and melon) its members can be accessed directly. The syntax for that is simply to insert a dot (.) between the object name and the member name. For example, we could operate with any of these elements as if they were standard variables of their respective types:
Each one of these has the data type corresponding to the member they refer to: apple.weight, banana.weight, and melon.weight are of type int, while apple.price, banana.price, and melon.price are of type double.
Here is a real example with structure types in action:
Enter title: Alien
Enter year: 1979
My favorite movie is:
2001 A Space Odyssey (1968)
And yours is:
Alien (1979)
The example shows how the members of an object act just as regular variables. For example, the member yours.year is a valid variable of type int, and mine.title is a valid variable of type string.
But the objects mine and yours are also variables with a type (of type movies_t). For example, both have been passed to function printmovie just as if they were simple variables. Therefore, one of the features of data structures is the ability to refer to both their members individually or to the entire structure as a whole. In both cases using the same identifier: the name of the structure.
Because structures are types, they can also be used as the type of arrays to construct tables or databases of them:
Enter title: Blade Runner
Enter year: 1982
Enter title: The Matrix
Enter year: 1999
Enter title: Taxi Driver
Enter year: 1976
You have entered these movies:
Blade Runner (1982)
The Matrix (1999)
Taxi Driver (1976)
Pointers to structures
Like any other type, structures can be pointed to by its own type of pointers:
Here amovie is an object of structure type movies_t, and pmovie is a pointer to point to objects of structure type movies_t. Therefore, the following code would also be valid:
pmovie = &amovie;
The value of the pointer pmovie would be assigned the address of object amovie.
Now, let's see another example that mixes pointers and structures, and will serve to introduce a new operator: the arrow operator (->):
Enter title: Invasion of the body snatchers
Enter year: 1978
You have entered:
Invasion of the body snatchers (1978)
The arrow operator (->) is a dereference operator that is used exclusively with pointers to objects that have members. This operator serves to access the member of an object directly from its address. For example, in the example above:
pmovie->title
is, for all purposes, equivalent to:
(*pmovie).title
Both expressions, pmovie->title and (*pmovie).title are valid, and both access the member title of the data structure pointed by a pointer called pmovie. It is definitely something different than:
*pmovie.title
which is rather equivalent to:
*(pmovie.title)
This would access the value pointed by a hypothetical pointer member called title of the structure object pmovie (which is not the case, since title is not a pointer type). The following panel summarizes possible combinations of the operators for pointers and for structure members:
| Expression | What is evaluated | Equivalent |
|---|---|---|
a.b | Member b of object a | |
a->b | Member b of object pointed to by a | (*a).b |
*a.b | Value pointed to by member b of object a | *(a.b) |
Nesting structures
Structures can also be nested in such a way that an element of a structure is itself another structure:
After the previous declarations, all of the following expressions would be valid:
(where, by the way, the last two expressions refer to the same member).
15 - C++ CLASSES (1)
Classes are an expanded concept of data structures: like data structures, they can contain data members, but they can also contain functions as members.
An object is an instantiation of a class. In terms of variables, a class would be the type, and an object would be the variable.
Classes are defined using either keyword class or keyword struct, with the following syntax:
Where class_name is a valid identifier for the class, object_names is an optional list of names for objects of this class. The body of the declaration can contain members, which can either be data or function declarations, and optionally access specifiers.
Classes have the same format as plain data structures, except that they can also include functions and have these new things called access specifiers. An access specifier is one of the following three keywords: private, public or protected. These specifiers modify the access rights for the members that follow them:
- private members of a class are accessible only from within other members of the same class (or from their "friends").
- protected members are accessible from other members of the same class (or from their "friends"), but also from members of their derived classes.
- Finally, public members are accessible from anywhere where the object is visible.
By default, all members of a class declared with the class keyword have private access for all its members. Therefore, any member that is declared before any other access specifier has private access automatically. For example:
Declares a class (i.e., a type) called Rectangle and an object (i.e., a variable) of this class, called rect. This class contains four members: two data members of type int (member width and member height) with private access (because private is the default access level) and two member functions with public access: the functions set_values and area, of which for now we have only included their declaration, but not their definition.
Notice the difference between the class name and the object name: In the previous example, Rectangle was the class name (i.e., the type), whereas rect was an object of type Rectangle. It is the same relationship int and a have in the following declaration:
int a;
where int is the type name (the class) and a is the variable name (the object).
After the declarations of Rectangle and rect, any of the public members of object rect can be accessed as if they were normal functions or normal variables, by simply inserting a dot (.) between object name and member name. This follows the same syntax as accessing the members of plain data structures. For example:
rect.set_values (3,4);
myarea = rect.area();
The only members of rect that cannot be accessed from outside the class are width and height, since they have private access and they can only be referred to from within other members of that same class.
Here is the complete example of class Rectangle:
area: 12
This example reintroduces the scope operator (::, two colons), seen in earlier chapters in relation to namespaces. Here it is used in the definition of function set_values to define a member of a class outside the class itself.
Notice that the definition of the member function area has been included directly within the definition of class Rectangle given its extreme simplicity. Conversely, set_values it is merely declared with its prototype within the class, but its definition is outside it. In this outside definition, the operator of scope (::) is used to specify that the function being defined is a member of the class Rectangle and not a regular non-member function.
The scope operator (::) specifies the class to which the member being declared belongs, granting exactly the same scope properties as if this function definition was directly included within the class definition. For example, the function set_values in the previous example has access to the variables width and height, which are private members of class Rectangle, and thus only accessible from other members of the class, such as this.
The only difference between defining a member function completely within the class definition or to just include its declaration in the function and define it later outside the class, is that in the first case the function is automatically considered an inline member function by the compiler, while in the second it is a normal (not-inline) class member function. This causes no differences in behavior, but only on possible compiler optimizations.
Members width and height have private access (remember that if nothing else is specified, all members of a class defined with keyword class have private access). By declaring them private, access from outside the class is not allowed. This makes sense, since we have already defined a member function to set values for those members within the object: the member function set_values. Therefore, the rest of the program does not need to have direct access to them. Perhaps in a so simple example as this, it is difficult to see how restricting access to these variables may be useful, but in greater projects it may be very important that values cannot be modified in an unexpected way (unexpected from the point of view of the object).
The most important property of a class is that it is a type, and as such, we can declare multiple objects of it. For example, following with the previous example of class Rectangle, we could have declared the object rectb in addition to object rect:
n this particular case, the class (type of the objects) is Rectangle, of which there are two instances (i.e., objects): rect and rectb. Each one of them has its own member variables and member functions.
Notice that the call to rect.area() does not give the same result as the call to rectb.area(). This is because each object of class Rectangle has its own variables width and height, as they -in some way- have also their own function members set_value and area that operate on the object's own member variables.
Classes allow programming using object-oriented paradigms: Data and functions are both members of the object, reducing the need to pass and carry handlers or other state variables as arguments to functions, because they are part of the object whose member is called. Notice that no arguments were passed on the calls to rect.area or rectb.area. Those member functions directly used the data members of their respective objects rect and rectb.
Constructors
What would happen in the previous example if we called the member function area before having called set_values? An undetermined result, since the members width and height had never been assigned a value.
In order to avoid that, a class can include a special function called its constructor, which is automatically called whenever a new object of this class is created, allowing the class to initialize member variables or allocate storage.
This constructor function is declared just like a regular member function, but with a name that matches the class name and without any return type; not even void.
The Rectangle class above can easily be improved by implementing a constructor:
rect area: 12
rectb area: 30
The results of this example are identical to those of the previous example. But now, class Rectangle has no member function set_values, and has instead a constructor that performs a similar action: it initializes the values of width and height with the arguments passed to it.
Notice how these arguments are passed to the constructor at the moment at which the objects of this class are created:
Rectangle rect (3,4);
Rectangle rectb (5,6);
Constructors cannot be called explicitly as if they were regular member functions. They are only executed once, when a new object of that class is created.
Notice how neither the constructor prototype declaration (within the class) nor the latter constructor definition, have return values; not even void: Constructors never return values, they simply initialize the object.
Overloading constructors
Like any other function, a constructor can also be overloaded with different versions taking different parameters: with a different number of parameters and/or parameters of different types. The compiler will automatically call the one whose parameters match the arguments:
In the above example, two objects of class Rectangle are constructed: rect and rectb. rect is constructed with two arguments, like in the example before. But this example also introduces a special kind constructor: the default constructor. The default constructor is the constructor that takes no parameters, and it is special because it is called when an object is declared but is not initialized with any arguments. In the example above, the default constructor is called for rectb. Note how rectb is not even constructed with an empty set of parentheses - in fact, empty parentheses cannot be used to call the default constructor:
This is because the empty set of parentheses would make of rectc a function declaration instead of an object declaration: It would be a function that takes no arguments and returns a value of type Rectangle.
Uniform initialization
The way of calling constructors by enclosing their arguments in parentheses, as shown above, is known as functional form. But constructors can also be called with other syntaxes:
First, constructors with a single parameter can be called using the variable initialization syntax (an equal sign followed by the argument):
class_name object_name = initialization_value;
More recently, C++ introduced the possibility of constructors to be called using uniform initialization, which essentially is the same as the functional form, but using braces ({}) instead of parentheses (()):
class_name object_name { value, value, value, ... }
Optionally, this last syntax can include an equal sign before the braces.
Here is an example with four ways to construct objects of a class whose constructor takes a single parameter:
foo's circumference: 62.8319
An advantage of uniform initialization over functional form is that, unlike parentheses, braces cannot be confused with function declarations, and thus can be used to explicitly call default constructors:
The choice of syntax to call constructors is largely a matter of style. Most existing code currently uses functional form, and some newer style guides suggest to choose uniform initialization over the others, even though it also has its potential pitfalls for its preference of initializer_list as its type.
Member initialization in constructors
When a constructor is used to initialize other members, these other members can be initialized directly, without resorting to statements in its body. This is done by inserting, before the constructor's body, a colon (:) and a list of initializations for class members. For example, consider a class with the following declaration:
The constructor for this class could be defined, as usual, as:
Rectangle::Rectangle (int x, int y) { width=x; height=y; }
But it could also be defined using member initialization as:
Rectangle::Rectangle (int x, int y) : width(x) { height=y; }
Or even:
Rectangle::Rectangle (int x, int y) : width(x), height(y) { }
Note how in this last case, the constructor does nothing else than initialize its members, hence it has an empty function body.
For members of fundamental types, it makes no difference which of the ways above the constructor is defined, because they are not initialized by default, but for member objects (those whose type is a class), if they are not initialized after the colon, they are default-constructed.
Default-constructing all members of a class may or may always not be convenient: in some cases, this is a waste (when the member is then reinitialized otherwise in the constructor), but in some other cases, default-construction is not even possible (when the class does not have a default constructor). In these cases, members shall be initialized in the member initialization list. For example:
In this example, class Cylinder has a member object whose type is another class (base's type is Circle). Because objects of class Circle can only be constructed with a parameter, Cylinder's constructor needs to call base's constructor, and the only way to do this is in the member initializer list.
These initializations can also use uniform initializer syntax, using braces {} instead of parentheses ():
Pointers to classes
Objects can also be pointed to by pointers: Once declared, a class becomes a valid type, so it can be used as the type pointed to by a pointer. For example:
Rectangle * prect;
is a pointer to an object of class Rectangle. Similarly as with plain data structures, the members of an object can be accessed directly from a pointer by using the arrow operator (->). Here is an example with some possible combinations:
This example makes use of several operators to operate on objects and pointers (operators *, &, ., ->, []). They can be interpreted as:
| expression | can be read as |
|---|---|
*x | pointed to by x |
&x | address of x |
x.y | member y of object x |
x->y | member y of object pointed to by x |
(*x).y | member y of object pointed to by x (equivalent to the previous one) |
x[0] | first object pointed to by x |
x[1] | second object pointed to by x |
x[n] | (n+1)th object pointed to by x |
Most of these expressions have been introduced in earlier chapters. Most notably, the chapter about arrays introduced the offset operator ([]) and the chapter about plain data structures introduced the arrow operator (->).
Classes defined with struct and union
Classes can be defined not only with keyword class, but also with keywords struct and union.
The keyword struct, generally used to declare plain data structures, can also be used to declare classes that have member functions, with the same syntax as with keyword class. The only difference between both is that members of classes declared with the keyword struct have public access by default, while members of classes declared with the keyword class have private access by default. For all other purposes both keywords are equivalent in this context.
Conversely, the concept of unions is different from that of classes declared with struct and class, since unions only store one data member at a time, but nevertheless they are also classes and can thus also hold member functions. The default access in union classes is public.
16 - C++ CLASSES (2)
Overloading operators
Classes, essentially, define new types to be used in C++ code. And types in C++ not only interact with code by means of constructions and assignments. They also interact by means of operators. For example, take the following operation on fundamental types:
int a, b, c;
a = b + c;
Here, different variables of a fundamental type (int) are applied the addition operator, and then the assignment operator. For a fundamental arithmetic type, the meaning of such operations is generally obvious and unambiguous, but it may not be so for certain class types. For example:
struct myclass {
string product;
float price;
} a, b, c;
a = b + c;
Here, it is not obvious what the result of the addition operation on b and c does. In fact, this code alone would cause a compilation error, since the type myclass has no defined behavior for additions. However, C++ allows most operators to be overloaded so that their behavior can be defined for just about any type, including classes. Here is a list of all the operators that can be overloaded:
| Overloadable operators |
|---|
|
Operators are overloaded by means of operator functions, which are regular functions with special names: their name begins by the operator keyword followed by the operator sign that is overloaded. The syntax is:
type operator sign (parameters) { /*... body ...*/ }
For example, cartesian vectors are sets of two coordinates: x and y. The addition operation of two cartesian vectors is defined as the addition both x coordinates together, and both y coordinates together. For example, adding the cartesian vectors (3,1) and (1,2) together would result in (3+1,1+2) = (4,3). This could be implemented in C++ with the following code:
4,3
If confused about so many appearances of CVector, consider that some of them refer to the class name (i.e., the type) CVector and some others are functions with that name (i.e., constructors, which must have the same name as the class). For example:
The function operator+ of class CVector overloads the addition operator (+) for that type. Once declared, this function can be called either implicitly using the operator, or explicitly using its functional name:
Both expressions are equivalent.
The operator overloads are just regular functions which can have any behavior; there is actually no requirement that the operation performed by that overload bears a relation to the mathematical or usual meaning of the operator, although it is strongly recommended. For example, a class that overloads operator+ to actually subtract or that overloads operator== to fill the object with zeros, is perfectly valid, although using such a class could be challenging.
The parameter expected for a member function overload for operations such as operator+ is naturally the operand to the right hand side of the operator. This is common to all binary operators (those with an operand to its left and one operand to its right). But operators can come in diverse forms. Here you have a table with a summary of the parameters needed for each of the different operators than can be overloaded (please, replace @ by the operator in each case):
| Expression | Operator | Member function | Non-member function |
|---|---|---|---|
@a | + - * & ! ~ ++ -- | A::operator@() | operator@(A) |
a@ | ++ -- | A::operator@(int) | operator@(A,int) |
a@b | + - * / % ^ & | < > == != <= >= << >> && || , | A::operator@(B) | operator@(A,B) |
a@b | = += -= *= /= %= ^= &= |= <<= >>= [] | A::operator@(B) | - |
a(b,c...) | () | A::operator()(B,C...) | - |
a->b | -> | A::operator->() | - |
(TYPE) a | TYPE | A::operator TYPE() | - |
Where a is an object of class A, b is an object of class B and c is an object of class C. TYPE is just any type (that operators overloads the conversion to type TYPE).
Notice that some operators may be overloaded in two forms: either as a member function or as a non-member function: The first case has been used in the example above for operator+. But some operators can also be overloaded as non-member functions; In this case, the operator function takes an object of the proper class as first argument.
For example:
4,3
The keyword this
The keyword this represents a pointer to the object whose member function is being executed. It is used within a class's member function to refer to the object itself. One of its uses can be to check if a parameter passed to a member function is the object itself. For example:
yes, &a is b
It is also frequently used in operator= member functions that return objects by reference. Following with the examples on cartesian vector seen before, its operator= function could have been defined as:
In fact, this function is very similar to the code that the compiler generates implicitly for this class for operator=.
Static members
A class can contain static members, either data or functions.
A static data member of a class is also known as a "class variable", because there is only one common variable for all the objects of that same class, sharing the same value: i.e., its value is not different from one object of this class to another.
For example, it may be used for a variable within a class that can contain a counter with the number of objects of that class that are currently allocated, as in the following example:
6
7
In fact, static members have the same properties as non-member variables but they enjoy class scope. For that reason, and to avoid them to be declared several times, they cannot be initialized directly in the class, but need to be initialized somewhere outside it. As in the previous example:
int Dummy::n=0;
Because it is a common variable value for all the objects of the same class, it can be referred to as a member of any object of that class or even directly by the class name (of course this is only valid for static members):
cout << a.n;
cout << Dummy::n;
These two calls above are referring to the same variable: the static variable n within class Dummy shared by all objects of this class.
Again, it is just like a non-member variable, but with a name that requires to be accessed like a member of a class (or an object).
Classes can also have static member functions. These represent the same: members of a class that are common to all object of that class, acting exactly as non-member functions but being accessed like members of the class. Because they are like non-member functions, they cannot access non-static members of the class (neither member variables nor member functions). They neither can use the keyword this.
Const member functions
When an object of a class is qualified as a const object:
const MyClass myobject;
The access to its data members from outside the class is restricted to read-only, as if all its data members were const for those accessing them from outside the class. Note though, that the constructor is still called and is allowed to initialize and modify these data members:
10
The member functions of a const object can only be called if they are themselves specified as const members; in the example above, member get (which is not specified as const) cannot be called from foo. To specify that a member is a const member, the const keyword shall follow the function prototype, after the closing parenthesis for its parameters:
int get() const {return x;}
Note that const can be used to qualify the type returned by a member function. This const is not the same as the one which specifies a member as const. Both are independent and are located at different places in the function prototype:
int get() const {return x;} // const member function const int< get() {return x;} // member function returning a const< const int< get() const {return x;} // const member function returning a const<
Member functions specified to be const cannot modify non-static data members nor call other non-const member functions. In essence, const members shall not modify the state of an object.
const objects are limited to access only member functions marked as const, but non-const objects are not restricted and thus can access both const and non-const member functions alike.
You may think that anyway you are seldom going to declare const objects, and thus marking all members that don't modify the object as const is not worth the effort, but const objects are actually very common. Most functions taking classes as parameters actually take them by const reference, and thus, these functions can only access their const members:
10
If in this example, get was not specified as a const member, the call to arg.get() in the print function would not be possible, because const objects only have access to const member functions.
Member functions can be overloaded on their constness: i.e., a class may have two member functions with identical signatures except that one is const and the other is not: in this case, the const version is called only when the object is itself const, and the non-const version is called when the object is itself non-const.
15
20
Class templates
Just like we can create function templates, we can also create class templates, allowing classes to have members that use template parameters as types. For example:
template <class T> class mypair { T values [2]; public: mypair (T first, T second) { values[0]=first; values[1]=second; } };
The class that we have just defined serves to store two elements of any valid type. For example, if we wanted to declare an object of this class to store two integer values of type int with the values 115 and 36 we would write:
mypair<int> myobject (115, 36);
This same class could also be used to create an object to store any other type, such as:
mypair<double> myfloats (3.0, 2.18);
The constructor is the only member function in the previous class template and it has been defined inline within the class definition itself. In case that a member function is defined outside the defintion of the class template, it shall be preceded with the template <...> prefix:
100
Notice the syntax of the definition of member function getmax:
template <class T>
T mypair<T>::getmax ()
Confused by so many T's? There are three T's in this declaration: The first one is the template parameter. The second T refers to the type returned by the function. And the third T (the one between angle brackets) is also a requirement: It specifies that this function's template parameter is also the class template parameter.
Template specialization
It is possible to define a different implementation for a template when a specific type is passed as template argument. This is called a template specialization. For example, let's suppose that we have a very simple class called mycontainer that can store one element of any type and that has just one member function called increase, which increases its value. But we find that when it stores an element of type char it would be more convenient to have a completely different implementation with a function member uppercase, so we decide to declare a class template specialization for that type:
// template specialization #include <iostream> using namespace std; // class template: template <class T> class mycontainer { T element; public: mycontainer (T arg) {element=arg;} T increase () {return ++element;} }; // class template specialization: template <> class mycontainer <char> { char element; public: mycontainer (char arg) {element=arg;} char uppercase () { if ((element>='a')&&(element<='z')) element+='A'-'a'; return element; } }; int main () { mycontainer<int> myint (7); mycontainer<char> mychar ('j'); cout << myint.increase() << endl; cout << mychar.uppercase() << endl; return 0; }
8
J
This is the syntax used for the class template specialization:
template <> class mycontainer <char> { ... };
First of all, notice that we precede the class name with template<> , including an empty parameter list. This is because all types are known and no template arguments are required for this specialization, but still, it is the specialization of a class template, and thus it requires to be noted as such.
But more important than this prefix, is the <char> specialization parameter after the class template name. This specialization parameter itself identifies the type for which the template class is being specialized (char). Notice the differences between the generic class template and the specialization:
template <class T> class mycontainer { ... };
template <> class mycontainer <char> { ... };
The first line is the generic template, and the second one is the specialization.
When we declare specializations for a template class, we must also define all its members, even those identical to the generic template class, because there is no "inheritance" of members from the generic template to the specialization.
17 - C++ SPECIAL MEMBERS
[NOTE: This chapter requires proper understanding of dynamically allocated memory]Special member functions are member functions that are implicitly defined as member of classes under certain circumstances. There are six:
| Member function | typical form for class C: |
|---|---|
| Default constructor | C::C(); |
| Destructor | C::~C(); |
| Copy constructor | C::C (const C&); |
| Copy assignment | C& operator= (const C&); |
| Move constructor | C::C (C&&); |
| Move assignment | C& operator= (C&&); |
Let's examine each of these:
Default constructor
The default constructor is the constructor called when objects of a class are declared, but are not initialized with any arguments.
If a class definition has no constructors, the compiler assumes the class to have an implicitly defined default constructor. Therefore, after declaring a class like this:
The compiler assumes that Example has a default constructor. Therefore, objects of this class can be constructed by simply declaring them without any arguments:
But as soon as a class has some constructor taking any number of parameters explicitly declared, the compiler no longer provides an implicit default constructor, and no longer allows the declaration of new objects of that class without arguments. For example, the following class:
Here, we have declared a constructor with a parameter of type int. Therefore the following object declaration would be correct:
But the following:
Would not be valid, since the class has been declared with an explicit constructor taking one argument and that replaces the implicit default constructor taking none.
Therefore, if objects of this class need to be constructed without arguments, the proper default constructor shall also be declared in the class. For example:
bar's content: Example
Here, Example3 has a default constructor (i.e., a constructor without parameters) defined as an empty block:
This allows objects of class Example3 to be constructed without arguments (like foo was declared in this example). Normally, a default constructor like this is implicitly defined for all classes that have no other constructors and thus no explicit definition is required. But in this case, Example3 has another constructor:
Example3 (const string& str);
And when any constructor is explicitly declared in a class, no implicit default constructors is automatically provided.
Destructor
Destructors fulfill the opposite functionality of constructors: They are responsible for the necessary cleanup needed by a class when its lifetime ends. The classes we have defined in previous chapters did not allocate any resource and thus did not really require any clean up.
But now, let's imagine that the class in the last example allocates dynamic memory to store the string it had as data member; in this case, it would be very useful to have a function called automatically at the end of the object's life in charge of releasing this memory. To do this, we use a destructor. A destructor is a member function very similar to a default constructor: it takes no arguments and returns nothing, not even void. It also uses the class name as its own name, but preceded with a tilde sign (~):
bar's content: Example
On construction, Example4 allocates storage for a string. Storage that is later released by the destructor.
The destructor for an object is called at the end of its lifetime; in the case of foo and bar this happens at the end of function main.
Copy constructor
When an object is passed a named object of its own type as argument, its copy constructor is invoked in order to construct a copy.
A copy constructor is a constructor whose first parameter is of type reference to the class itself (possibly const qualified) and which can be invoked with a single argument of this type. For example, for a class MyClass, the copy constructor may have the following signature:
If a class has no custom copy nor move constructors (or assignments) defined, an implicit copy constructor is provided. This copy constructor simply performs a copy of its own members. For example, for a class such as:
An implicit copy constructor is automatically defined. The definition assumed for this function performs a shallow copy, roughly equivalent to:
This default copy constructor may suit the needs of many classes. But shallow copies only copy the members of the class themselves, and this is probably not what we expect for classes like class Example4 we defined above, because it contains pointers of which it handles its storage. For that class, performing a shallow copy means that the pointer value is copied, but not the content itself; This means that both objects (the copy and the original) would be sharing a single string object (they would both be pointing to the same object), and at some point (on destruction) both objects would try to delete the same block of memory, probably causing the program to crash on runtime. This can be solved by defining the following custom copy constructor that performs a deep copy:
bar's content: Example
The deep copy performed by this copy constructor allocates storage for a new string, which is initialized to contain a copy of the original object. In this way, both objects (copy and original) have distinct copies of the content stored in different locations.
Copy assignment
Objects are not only copied on construction, when they are initialized: They can also be copied on any assignment operation. See the difference:
Note that baz is initialized on construction using an equal sign, but this is not an assignment operation! (although it may look like one): The declaration of an object is not an assignment operation, it is just another of the syntaxes to call single-argument constructors.
The assignment on foo is an assignment operation. No object is being declared here, but an operation is being performed on an existing object; foo.
The copy assignment operator is an overload of operator= which takes a value or reference of the class itself as parameter. The return value is generally a reference to *this (although this is not required). For example, for a class MyClass, the copy assignment may have the following signature:
The copy assignment operator is also a special function and is also defined implicitly if a class has no custom copy nor move assignments (nor move constructor) defined.
But again, the implicit version performs a shallow copy which is suitable for many classes, but not for classes with pointers to objects they handle its storage, as is the case in Example5. In this case, not only the class incurs the risk of deleting the pointed object twice, but the assignment creates memory leaks by not deleting the object pointed by the object before the assignment. These issues could be solved with a copy assignment that deletes the previous object and performs a deep copy:
Or even better, since its string member is not constant, it could re-utilize the same string object:
Move constructor and assignment
Similar to copying, moving also uses the value of an object to set the value to another object. But, unlike copying, the content is actually transferred from one object (the source) to the other (the destination): the source loses that content, which is taken over by the destination. This moving only happens when the source of the value is an unnamed object.
Unnamed objects are objects that are temporary in nature, and thus haven't even been given a name. Typical examples of unnamed objects are return values of functions or type-casts.
Using the value of a temporary object such as these to initialize another object or to assign its value, does not really require a copy: the object is never going to be used for anything else, and thus, its value can be moved into the destination object. These cases trigger the move constructor and move assignments:
The move constructor is called when an object is initialized on construction using an unnamed temporary. Likewise, the move assignment is called when an object is assigned the value of an unnamed temporary:
Both the value returned by fn and the value constructed with MyClass are unnamed temporaries. In these cases, there is no need to make a copy, because the unnamed object is very short-lived and can be acquired by the other object when this is a more efficient operation.
The move constructor and move assignment are members that take a parameter of type rvalue reference to the class itself:
An rvalue reference is specified by following the type with two ampersands (&&). As a parameter, an rvalue reference matches arguments of temporaries of this type.
The concept of moving is most useful for objects that manage the storage they use, such as objects that allocate storage with new and delete. In such objects, copying and moving are really different operations:
- Copying from A to B means that new memory is allocated to B and then the entire content of A is copied to this new memory allocated for B.
- Moving from A to B means that the memory already allocated to A is transferred to B without allocating any new storage. It involves simply copying the pointer.
For example:
foo's content: Example
Compilers already optimize many cases that formally require a move-construction call in what is known as Return Value Optimization. Most notably, when the value returned by a function is used to initialize an object. In these cases, the move constructor may actually never get called.
Note that even though rvalue references can be used for the type of any function parameter, it is seldom useful for uses other than the move constructor. Rvalue references are tricky, and unnecessary uses may be the source of errors quite difficult to track.
Implicit members
The six special members functions described above are members implicitly declared on classes under certain circumstances:
| Member function | implicitly defined: | default definition: |
|---|---|---|
| Default constructor | if no other constructors | does nothing |
| Destructor | if no destructor | does nothing |
| Copy constructor | if no move constructor and no move assignment | copies all members |
| Copy assignment | if no move constructor and no move assignment | copies all members |
| Move constructor | if no destructor, no copy constructor and no copy nor move assignment | moves all members |
| Move assignment | if no destructor, no copy constructor and no copy nor move assignment | moves all members |
Notice how not all special member functions are implicitly defined in the same cases. This is mostly due to backwards compatibility with C structures and earlier C++ versions, and in fact some include deprecated cases. Fortunately, each class can select explicitly which of these members exist with their default definition or which are deleted by using the keywords default and delete, respectively. The syntax is either one of:
For example:
Here, Rectangle can be constructed either with two int arguments or be default-constructed (with no arguments). It cannot however be copy-constructed from another Rectangle object, because this function has been deleted. Therefore, assuming the objects of the last example, the following statement would not be valid:
It could, however, be made explicitly valid by defining its copy constructor as:
Which would be essentially equivalent to:
Note that, the keyword default does not define a member function equal to the default constructor (i.e., where default constructor means constructor with no parameters), but equal to the constructor that would be implicitly defined if not deleted. In general, and for future compatibility, classes that explicitly define one copy/move constructor or one copy/move assignment but not both, are encouraged to specify either delete or default on the other special member functions they don't explicitly define.
18 - C++ FRIENDSHIP AND INHERITANCE
Friend functions
In principle, private and protected members of a class cannot be accessed from outside the same class in which they are declared. However, this rule does not apply to "friends".
Friends are functions or classes declared with the friend keyword.
A non-member function can access the private and protected members of a class if it is declared a friend of that class. That is done by including a declaration of this external function within the class, and preceding it with the keyword friend:
24
The duplicate function is a friend of class Rectangle. Therefore, function duplicate is able to access the members width and height (which are private) of different objects of type Rectangle. Notice though that neither in the declaration of duplicate nor in its later use in main, function duplicate is considered a member of class Rectangle. It isn't! It simply has access to its private and protected members without being a member.
Typical use cases of friend functions are operations that are conducted between two different classes accessing private or protected members of both.
Friend classes
Similar to friend functions, a friend class is a class whose members have access to the private or protected members of another class:
16
In this example, class Rectangle is a friend of class Square allowing Rectangle's member functions to access private and protected members of Square. More concretely, Rectangle accesses the member variable Square::side, which describes the side of the square.
There is something else new in this example: at the beginning of the program, there is an empty declaration of class Square. This is necessary because class Rectangle uses Square (as a parameter in member convert), and Square uses Rectangle (declaring it a friend).
Friendships are never corresponded unless specified: In our example, Rectangle is considered a friend class by Square, but Square is not considered a friend by Rectangle. Therefore, the member functions of Rectangle can access the protected and private members of Square but not the other way around. Of course, Square could also be declared friend of Rectangle, if needed, granting such an access.
Another property of friendships is that they are not transitive: The friend of a friend is not considered a friend unless explicitly specified.
Inheritance between classes
Classes in C++ can be extended, creating new classes which retain characteristics of the base class. This process, known as inheritance, involves a base class and a derived class: The derived class inherits the members of the base class, on top of which it can add its own members.
For example, let's imagine a series of classes to describe two kinds of polygons: rectangles and triangles. These two polygons have certain common properties, such as the values needed to calculate their areas: they both can be described simply with a height and a width (or base).
This could be represented in the world of classes with a class Polygon from which we would derive the two other ones: Rectangle and Triangle:
The Polygon class would contain members that are common for both types of polygon. In our case: width and height. And Rectangle and Triangle would be its derived classes, with specific features that are different from one type of polygon to the other.
Classes that are derived from others inherit all the accessible members of the base class. That means that if a base class includes a member A and we derive a class from it with another member called B, the derived class will contain both member A and member B.
The inheritance relationship of two classes is declared in the derived class. Derived classes definitions use the following syntax:
class derived_class_name: public base_class_name
{ /*...*/ };
Where derived_class_name is the name of the derived class and base_class_name is the name of the class on which it is based. The public access specifier may be replaced by any one of the other access specifiers (protected or private). This access specifier limits the most accessible level for the members inherited from the base class: The members with a more accessible level are inherited with this level instead, while the members with an equal or more restrictive access level keep their restrictive level in the derived class.
20
10
The objects of the classes Rectangle and Triangle each contain members inherited from Polygon. These are: width, height and set_values.
The protected access specifier used in class Polygon is similar to private. Its only difference occurs in fact with inheritance: When a class inherits another one, the members of the derived class can access the protected members inherited from the base class, but not its private members.
By declaring width and height as protected instead of private, these members are also accessible from the derived classes Rectangle and Triangle, instead of just from members of Polygon. If they were public, they could be accessed just from anywhere.
We can summarize the different access types according to which functions can access them in the following way:
| Access | public | protected | private |
|---|---|---|---|
| members of the same class | yes | yes | yes |
| members of derived class | yes | yes | no |
| not members | yes | no | no |
Where "not members" represents any access from outside the class, such as from main, from another class or from a function.
In the example above, the members inherited by Rectangle and Triangle have the same access permissions as they had in their base class Polygon:
This is because the inheritance relation has been declared using the public keyword on each of the derived classes:
This public keyword after the colon (:) denotes the most accessible level the members inherited from the class that follows it (in this case Polygon) will have from the derived class (in this case Rectangle). Since public is the most accessible level, by specifying this keyword the derived class will inherit all the members with the same levels they had in the base class.
With protected, all public members of the base class are inherited as protected in the derived class. Conversely, if the most restricting access level is specified (private), all the base class members are inherited as private.
For example, if daughter were a class derived from mother that we defined as:
This would set protected as the less restrictive access level for the members of Daughter that it inherited from mother. That is, all members that were public in Mother would become protected in Daughter. Of course, this would not restrict Daughter from declaring its own public members. That less restrictive access level is only set for the members inherited from Mother.
If no access level is specified for the inheritance, the compiler assumes private for classes declared with keyword class and public for those declared with struct.
Actually, most use cases of inheritance in C++ should use public inheritance. When other access levels are needed for base classes, they can usually be better represented as member variables instead.
What is inherited from the base class?
In principle, a publicly derived class inherits access to every member of a base class except:
- its constructors and its destructor
- its assignment operator members (operator=)
- its friends
- its private members
Even though access to the constructors and destructor of the base class is not inherited as such, they are automatically called by the constructors and destructor of the derived class.
Unless otherwise specified, the constructors of a derived class calls the default constructor of its base classes (i.e., the constructor taking no arguments). Calling a different constructor of a base class is possible, using the same syntax used to initialize member variables in the initialization list:
derived_constructor_name (parameters) : base_constructor_name (parameters) {...}
For example:
Notice the difference between which Mother's constructor is called when a new Daughter object is created and which when it is a Son object. The difference is due to the different constructor declarations of Daughter and Son:
Multiple inheritance
A class may inherit from more than one class by simply specifying more base classes, separated by commas, in the list of a class's base classes (i.e., after the colon). For example, if the program had a specific class to print on screen called Output, and we wanted our classes Rectangle and Triangle to also inherit its members in addition to those of Polygon we could write:
Here is the complete example:
20
10
19 - C++ POLYMORPHISM
Before getting any deeper into this chapter, you should have a proper understanding of pointers and class inheritance. If you are not really sure of the meaning of any of the following expressions, you should review the indicated sections:
| Statement: | Explained in: |
|---|---|
int A::b(int c) { } | Classes |
a->b | Data structures |
class A: public B {}; | Friendship and inheritance |
Pointers to base class
One of the key features of class inheritance is that a pointer to a derived class is type-compatible with a pointer to its base class. Polymorphism is the art of taking advantage of this simple but powerful and versatile feature.
The example about the rectangle and triangle classes can be rewritten using pointers taking this feature into account:
20
10
Function main declares two pointers to Polygon (named ppoly1 and ppoly2). These are assigned the addresses of rect and trgl, respectively, which are objects of type Rectangle and Triangle. Such assignments are valid, since both Rectangle and Triangle are classes derived from Polygon.
Dereferencing ppoly1 and ppoly2 (with *ppoly1 and *ppoly2) is valid and allows us to access the members of their pointed objects. For example, the following two statements would be equivalent in the previous example:
But because the type of ppoly1 and ppoly2 is pointer to Polygon (and not pointer to Rectangle nor pointer to Triangle), only the members inherited from Polygon can be accessed, and not those of the derived classes Rectangle and Triangle. That is why the program above accesses the area members of both objects using rect and trgl directly, instead of the pointers; the pointers to the base class cannot access the area members.
Member area could have been accessed with the pointers to Polygon if area were a member of Polygon instead of a member of its derived classes, but the problem is that Rectangle and Triangle implement different versions of area, therefore there is not a single common version that could be implemented in the base class.
Virtual members
A virtual member is a member function that can be redefined in a derived class, while preserving its calling properties through references. The syntax for a function to become virtual is to precede its declaration with the virtual keyword:
20
10
0
In this example, all three classes (Polygon, Rectangle and Triangle) have the same members: width, height, and functions set_values and area.
The member function area has been declared as virtual in the base class because it is later redefined in each of the derived classes. Non-virtual members can also be redefined in derived classes, but non-virtual members of derived classes cannot be accessed through a reference of the base class: i.e., if virtual is removed from the declaration of area in the example above, all three calls to area would return zero, because in all cases, the version of the base class would have been called instead.
Therefore, essentially, what the virtual keyword does is to allow a member of a derived class with the same name as one in the base class to be appropriately called from a pointer, and more precisely when the type of the pointer is a pointer to the base class that is pointing to an object of the derived class, as in the above example.
A class that declares or inherits a virtual function is called a polymorphic class.
Note that despite of the virtuality of one of its members, Polygon was a regular class, of which even an object was instantiated (poly), with its own definition of member area that always returns 0.
Abstract base classes
Abstract base classes are something very similar to the Polygon class in the previous example. They are classes that can only be used as base classes, and thus are allowed to have virtual member functions without definition (known as pure virtual functions). The syntax is to replace their definition by =0 (an equal sign and a zero):
An abstract base Polygon class could look like this:
Notice that area has no definition; this has been replaced by =0, which makes it a pure virtual function. Classes that contain at least one pure virtual function are known as abstract base classes.
Abstract base classes cannot be used to instantiate objects. Therefore, this last abstract base class version of Polygon could not be used to declare objects like:
But an abstract base class is not totally useless. It can be used to create pointers to it, and take advantage of all its polymorphic abilities. For example, the following pointer declarations would be valid:
And can actually be dereferenced when pointing to objects of derived (non-abstract) classes. Here is the entire example:
// abstract base class #include <iostream> using namespace std; class Polygon { protected: int width, height; public: void set_values (int a, int b) { width=a; height=b; } virtual int area (void) =0; }; class Rectangle: public Polygon { public: int area (void) { return (width * height); } }; class Triangle: public Polygon { public: int area (void) { return (width * height / 2); } }; int main () { Rectangle rect; Triangle trgl; Polygon * ppoly1 = ▭ Polygon * ppoly2 = &trgl; ppoly1->set_values (4,5); ppoly2->set_values (4,5); cout << ppoly1->area() << '\n'; cout << ppoly2->area() << '\n'; return 0; }
20
10
In this example, objects of different but related types are referred to using a unique type of pointer (Polygon*) and the proper member function is called every time, just because they are virtual. This can be really useful in some circumstances. For example, it is even possible for a member of the abstract base class Polygon to use the special pointer this to access the proper virtual members, even though Polygon itself has no implementation for this function:
20
10
Virtual members and abstract classes grant C++ polymorphic characteristics, most useful for object-oriented projects. Of course, the examples above are very simple use cases, but these features can be applied to arrays of objects or dynamically allocated objects.
Here is an example that combines some of the features in the latest chapters, such as dynamic memory, constructor initializers and polymorphism:
20
10
Notice that the ppoly pointers:
are declared being of type "pointer to Polygon", but the objects allocated have been declared having the derived class type directly (Rectangle and Triangle).
20 - C++ TYPE CONVERSIONS
Implicit conversion
Implicit conversions are automatically performed when a value is copied to a compatible type. For example:
Here, the value of a is promoted from short to int without the need of any explicit operator. This is known as a standard conversion. Standard conversions affect fundamental data types, and allow the conversions between numerical types (short to int, int to float, double to int...), to or from bool, and some pointer conversions.
Converting to int from some smaller integer type, or to double from float is known as promotion, and is guaranteed to produce the exact same value in the destination type. Other conversions between arithmetic types may not always be able to represent the same value exactly:
- If a negative integer value is converted to an unsigned type, the resulting value corresponds to its 2's complement bitwise representation (i.e., -1 becomes the largest value representable by the type, -2 the second largest, ...).
- The conversions from/to bool consider false equivalent to zero (for numeric types) and to null pointer (for pointer types); true is equivalent to all other values and is converted to the equivalent of 1.
- If the conversion is from a floating-point type to an integer type, the value is truncated (the decimal part is removed). If the result lies outside the range of representable values by the type, the conversion causes undefined behavior.
- Otherwise, if the conversion is between numeric types of the same kind (integer-to-integer or floating-to-floating), the conversion is valid, but the value is implementation-specific (and may not be portable).
Some of these conversions may imply a loss of precision, which the compiler can signal with a warning. This warning can be avoided with an explicit conversion.
For non-fundamental types, arrays and functions implicitly convert to pointers, and pointers in general allow the following conversions:
- Null pointers can be converted to pointers of any type
- Pointers to any type can be converted to void pointers.
- Pointer upcast: pointers to a derived class can be converted to a pointer of an accessible and unambiguous base class, without modifying its const or volatile qualification.
Implicit conversions with classes
In the world of classes, implicit conversions can be controlled by means of three member functions:
- Single-argument constructors: allow implicit conversion from a particular type to initialize an object.
- Assignment operator: allow implicit conversion from a particular type on assignments.
- Type-cast operator: allow implicit conversion to a particular type.
For example:
The type-cast operator uses a particular syntax: it uses the operator keyword followed by the destination type and an empty set of parentheses. Notice that the return type is the destination type and thus is not specified before the operator keyword.
Keyword explicit
On a function call, C++ allows one implicit conversion to happen for each argument. This may be somewhat problematic for classes, because it is not always what is intended. For example, if we add the following function to the last example:
This function takes an argument of type B, but it could as well be called with an object of type A as argument:
This may or may not be what was intended. But, in any case, it can be prevented by marking the affected constructor with the explicit keyword:
Additionally, constructors marked with explicit cannot be called with the assignment-like syntax; In the above example, bar could not have been constructed with:
Type-cast member functions (those described in the previous section) can also be specified as explicit. This prevents implicit conversions in the same way as explicit-specified constructors do for the destination type.
Type casting
C++ is a strong-typed language. Many conversions, specially those that imply a different interpretation of the value, require an explicit conversion, known in C++ as type-casting. There exist two main syntaxes for generic type-casting: functional and c-like:
The functionality of these generic forms of type-casting is enough for most needs with fundamental data types. However, these operators can be applied indiscriminately on classes and pointers to classes, which can lead to code that -while being syntactically correct- can cause runtime errors. For example, the following code compiles without errors:
The program declares a pointer to Addition, but then it assigns to it a reference to an object of another unrelated type using explicit type-casting:
Unrestricted explicit type-casting allows to convert any pointer into any other pointer type, independently of the types they point to. The subsequent call to member result will produce either a run-time error or some other unexpected results. In order to control these types of conversions between classes, we have four specific casting operators: dynamic_cast, reinterpret_cast, static_cast and const_cast. Their format is to follow the new type enclosed between angle-brackets (<>) and immediately after, the expression to be converted between parentheses. dynamic_cast <new_type> (expression) reinterpret_cast <new_type> (expression) static_cast <new_type> (expression) const_cast <new_type> (expression) The traditional type-casting equivalents to these expressions would be: (new_type) expression new_type (expression) but each one with its own special characteristics:
dynamic_cast
dynamic_cast can only be used with pointers and references to classes (or with void*). Its purpose is to ensure that the result of the type conversion points to a valid complete object of the destination pointer type.
This naturally includes pointer upcast (converting from pointer-to-derived to pointer-to-base), in the same way as allowed as an implicit conversion.
But dynamic_cast can also downcast (convert from pointer-to-base to pointer-to-derived) polymorphic classes (those with virtual members) if -and only if- the pointed object is a valid complete object of the target type. For example:
Null pointer on second type-cast.
Compatibility note: This type of dynamic_cast requires Run-Time Type Information (RTTI) to keep track of dynamic types. Some compilers support this feature as an option which is disabled by default. This needs to be enabled for runtime type checking using dynamic_cast to work properly with these types.The code above tries to perform two dynamic casts from pointer objects of type Base* (pba and pbb) to a pointer object of type Derived*, but only the first one is successful. Notice their respective initializations:
Even though both are pointers of type Base*, pba actually points to an object of type Derived, while pbb points to an object of type Base. Therefore, when their respective type-casts are performed using dynamic_cast, pba is pointing to a full object of class Derived, whereas pbb is pointing to an object of class Base, which is an incomplete object of class Derived.
When dynamic_cast cannot cast a pointer because it is not a complete object of the required class -as in the second conversion in the previous example- it returns a null pointer to indicate the failure. If dynamic_cast is used to convert to a reference type and the conversion is not possible, an exception of type bad_cast is thrown instead.
dynamic_cast can also perform the other implicit casts allowed on pointers: casting null pointers between pointers types (even between unrelated classes), and casting any pointer of any type to a void* pointer.
static_cast
static_cast can perform conversions between pointers to related classes, not only upcasts (from pointer-to-derived to pointer-to-base), but also downcasts (from pointer-to-base to pointer-to-derived). No checks are performed during runtime to guarantee that the object being converted is in fact a full object of the destination type. Therefore, it is up to the programmer to ensure that the conversion is safe. On the other side, it does not incur the overhead of the type-safety checks of dynamic_cast.
This would be valid code, although b would point to an incomplete object of the class and could lead to runtime errors if dereferenced.
Therefore, static_cast is able to perform with pointers to classes not only the conversions allowed implicitly, but also their opposite conversions.
static_cast is also able to perform all conversions allowed implicitly (not only those with pointers to classes), and is also able to perform the opposite of these. It can:
- Convert from void* to any pointer type. In this case, it guarantees that if the void* value was obtained by converting from that same pointer type, the resulting pointer value is the same.
- Convert integers, floating-point values and enum types to enum types.
Additionally, static_cast can also perform the following:
- Explicitly call a single-argument constructor or a conversion operator.
- Convert to rvalue references.
- Convert enum class values into integers or floating-point values.
- Convert any type to void, evaluating and discarding the value.
reinterpret_cast
reinterpret_cast converts any pointer type to any other pointer type, even of unrelated classes. The operation result is a simple binary copy of the value from one pointer to the other. All pointer conversions are allowed: neither the content pointed nor the pointer type itself is checked.
It can also cast pointers to or from integer types. The format in which this integer value represents a pointer is platform-specific. The only guarantee is that a pointer cast to an integer type large enough to fully contain it (such as intptr_t), is guaranteed to be able to be cast back to a valid pointer.
The conversions that can be performed by reinterpret_cast but not by static_cast are low-level operations based on reinterpreting the binary representations of the types, which on most cases results in code which is system-specific, and thus non-portable. For example:
This code compiles, although it does not make much sense, since now b points to an object of a totally unrelated and likely incompatible class. Dereferencing b is unsafe.
const_cast
This type of casting manipulates the constness of the object pointed by a pointer, either to be set or to be removed. For example, in order to pass a const pointer to a function that expects a non-const argument:
sample text
The example above is guaranteed to work because function print does not write to the pointed object. Note though, that removing the constness of a pointed object to actually write to it causes undefined behavior.
typeid
typeid allows to check the type of an expression:
typeid (expression)
This operator returns a reference to a constant object of type type_info that is defined in the standard header <typeinfo>. A value returned by typeid can be compared with another value returned by typeid using operators == and != or can serve to obtain a null-terminated character sequence representing the data type or class name by using its name() member.
a and b are of different types:
a is: int *
b is: int
When typeid is applied to classes, typeid uses the RTTI to keep track of the type of dynamic objects. When typeid is applied to an expression whose type is a polymorphic class, the result is the type of the most derived complete object:
a is: class Base *
b is: class Base *
*a is: class Base
*b is: class Derived
Note: The string returned by member name of type_info depends on the specific implementation of your compiler and library. It is not necessarily a simple string with its typical type name, like in the compiler used to produce this output.
Notice how the type that typeid considers for pointers is the pointer type itself (both a and b are of type class Base *). However, when typeid is applied to objects (like *a and *b) typeid yields their dynamic type (i.e. the type of their most derived complete object).
If the type typeid evaluates is a pointer preceded by the dereference operator (*), and this pointer has a null value, typeid throws a bad_typeid exception.
21 - C++ EXCEPTIONS
Exceptions provide a way to react to exceptional circumstances (like runtime errors) in programs by transferring control to special functions called handlers.
To catch exceptions, a portion of code is placed under exception inspection. This is done by enclosing that portion of code in a try-block. When an exceptional circumstance arises within that block, an exception is thrown that transfers the control to the exception handler. If no exception is thrown, the code continues normally and all handlers are ignored.
An exception is thrown by using the throw keyword from inside the try block. Exception handlers are declared with the keyword catch, which must be placed immediately after the try block:
An exception occurred. Exception Nr. 20
The code under exception handling is enclosed in a try block. In this example this code simply throws an exception:
A throw expression accepts one parameter (in this case the integer value 20), which is passed as an argument to the exception handler.
The exception handler is declared with the catch keyword immediately after the closing brace of the try block. The syntax for catch is similar to a regular function with one parameter. The type of this parameter is very important, since the type of the argument passed by the throw expression is checked against it, and only in the case they match, the exception is caught by that handler.
Multiple handlers (i.e., catch expressions) can be chained; each one with a different parameter type. Only the handler whose argument type matches the type of the exception specified in the throw statement is executed.
If an ellipsis (...) is used as the parameter of catch, that handler will catch any exception no matter what the type of the exception thrown. This can be used as a default handler that catches all exceptions not caught by other handlers:
In this case, the last handler would catch any exception thrown of a type that is neither int nor char.
After an exception has been handled the program, execution resumes after the try-catch block, not after the throw statement!.
It is also possible to nest try-catch blocks within more external try blocks. In these cases, we have the possibility that an internal catch block forwards the exception to its external level. This is done with the expression throw; with no arguments. For example:
Exception specification
Older code may contain dynamic exception specifications. They are now deprecated in C++, but still supported. A dynamic exception specification follows the declaration of a function, appending a throw specifier to it. For example:
This declares a function called myfunction, which takes one argument of type char and returns a value of type double. If this function throws an exception of some type other than int, the function calls std::unexpected instead of looking for a handler or calling std::terminate.
If this throw specifier is left empty with no type, this means that std::unexpected is called for any exception. Functions with no throw specifier (regular functions) never call std::unexpected, but follow the normal path of looking for their exception handler.
Standard exceptions
The C++ Standard library provides a base class specifically designed to declare objects to be thrown as exceptions. It is called std::exception and is defined in the <exception> header. This class has a virtual member function called what that returns a null-terminated character sequence (of type char *) and that can be overwritten in derived classes to contain some sort of description of the exception.
My exception happened.
We have placed a handler that catches exception objects by reference (notice the ampersand & after the type), therefore this catches also classes derived from exception, like our myex object of type myexception.
All exceptions thrown by components of the C++ Standard library throw exceptions derived from this exception class. These are:
| exception | description |
|---|---|
bad_alloc | thrown by new on allocation failure |
bad_cast | thrown by dynamic_cast when it fails in a dynamic cast |
bad_exception | thrown by certain dynamic exception specifiers |
bad_typeid | thrown by typeid |
bad_function_call | thrown by empty function objects |
bad_weak_ptr | thrown by shared_ptr when passed a bad weak_ptr |
Also deriving from exception, header <exception> defines two generic exception types that can be inherited by custom exceptions to report errors:
| exception | description |
|---|---|
logic_error | error related to the internal logic of the program |
runtime_error | error detected during runtime |
A typical example where standard exceptions need to be checked for is on memory allocation:
The exception that may be caught by the exception handler in this example is a bad_alloc. Because bad_alloc is derived from the standard base class exception, it can be caught (capturing by reference, captures all related classes).
22 - C++ PREPROCESSOR DIRECTIVE
Preprocessor directives are lines included in the code of programs preceded by a hash sign (#). These lines are not program statements but directives for the preprocessor. The preprocessor examines the code before actual compilation of code begins and resolves all these directives before any code is actually generated by regular statements.
These preprocessor directives extend only across a single line of code. As soon as a newline character is found, the preprocessor directive is ends. No semicolon (;) is expected at the end of a preprocessor directive. The only way a preprocessor directive can extend through more than one line is by preceding the newline character at the end of the line by a backslash (\).
macro definitions (#define, #undef)
To define preprocessor macros we can use #define. Its syntax is:
#define identifier replacement
When the preprocessor encounters this directive, it replaces any occurrence of identifier in the rest of the code by replacement. This replacement can be an expression, a statement, a block or simply anything. The preprocessor does not understand C++ proper, it simply replaces any occurrence of identifier by replacement.
After the preprocessor has replaced TABLE_SIZE, the code becomes equivalent to:
#define can work also with parameters to define function macros:
This would replace any occurrence of getmax followed by two arguments by the replacement expression, but also replacing each argument by its identifier, exactly as you would expect if it was a function:
5
7
Defined macros are not affected by block structure. A macro lasts until it is undefined with the #undef preprocessor directive:
This would generate the same code as:
Function macro definitions accept two special operators (# and ##) in the replacement sequence:
The operator #, followed by a parameter name, is replaced by a string literal that contains the argument passed (as if enclosed between double quotes):
This would be translated into:
The operator ## concatenates two arguments leaving no blank spaces between them:
This would also be translated into:
Because preprocessor replacements happen before any C++ syntax check, macro definitions can be a tricky feature. But, be careful: code that relies heavily on complicated macros become less readable, since the syntax expected is on many occasions different from the normal expressions programmers expect in C++.
Conditional inclusions (#ifdef, #ifndef, #if, #endif, #else and #elif)
These directives allow to include or discard part of the code of a program if a certain condition is met.
#ifdef allows a section of a program to be compiled only if the macro that is specified as the parameter has been defined, no matter which its value is. For example:
In this case, the line of code int table[TABLE_SIZE]; is only compiled if TABLE_SIZE was previously defined with #define, independently of its value. If it was not defined, that line will not be included in the program compilation.
#ifndef serves for the exact opposite: the code between #ifndef and #endif directives is only compiled if the specified identifier has not been previously defined. For example:
In this case, if when arriving at this piece of code, the TABLE_SIZE macro has not been defined yet, it would be defined to a value of 100. If it already existed it would keep its previous value since the #define directive would not be executed.
The #if, #else and #elif (i.e., "else if") directives serve to specify some condition to be met in order for the portion of code they surround to be compiled. The condition that follows #if or #elif can only evaluate constant expressions, including macro expressions. For example:
Notice how the entire structure of #if, #elif and #else chained directives ends with #endif.
The behavior of #ifdef and #ifndef can also be achieved by using the special operators defined and !defined respectively in any #if or #elif directive:
Line control (#line)
When we compile a program and some error happens during the compiling process, the compiler shows an error message with references to the name of the file where the error happened and a line number, so it is easier to find the code generating the error.
The #line directive allows us to control both things, the line numbers within the code files as well as the file name that we want that appears when an error takes place. Its format is:
#line number "filename"
Where number is the new line number that will be assigned to the next code line. The line numbers of successive lines will be increased one by one from this point on.
"filename" is an optional parameter that allows to redefine the file name that will be shown. For example:
This code will generate an error that will be shown as error in file "assigning variable", line 20.
Error directive (#error)
This directive aborts the compilation process when it is found, generating a compilation error that can be specified as its parameter:
This example aborts the compilation process if the macro name __cplusplus is not defined (this macro name is defined by default in all C++ compilers).
Source file inclusion (#include)
This directive has been used assiduously in other sections of this tutorial. When the preprocessor finds an #include directive it replaces it by the entire content of the specified header or file. There are two ways to use #include:
In the first case, a header is specified between angle-brackets <>. This is used to include headers provided by the implementation, such as the headers that compose the standard library (iostream, string,...). Whether the headers are actually files or exist in some other form is implementation-defined, but in any case they shall be properly included with this directive.
The syntax used in the second #include uses quotes, and includes a file. The file is searched for in an implementation-defined manner, which generally includes the current path. In the case that the file is not found, the compiler interprets the directive as a header inclusion, just as if the quotes ("") were replaced by angle-brackets (<>).
Pragma directive (#pragma)
This directive is used to specify diverse options to the compiler. These options are specific for the platform and the compiler you use. Consult the manual or the reference of your compiler for more information on the possible parameters that you can define with #pragma.
If the compiler does not support a specific argument for #pragma, it is ignored - no syntax error is generated.
Predefined macro names
The following macro names are always defined (they all begin and end with two underscore characters, _):
| macro | value |
|---|---|
__LINE__ | Integer value representing the current line in the source code file being compiled. |
__FILE__ | A string literal containing the presumed name of the source file being compiled. |
__DATE__ | A string literal in the form "Mmm dd yyyy" containing the date in which the compilation process began. |
__TIME__ | A string literal in the form "hh:mm:ss" containing the time at which the compilation process began. |
__cplusplus | An integer value. All C++ compilers have this constant defined to some value. Its value depends on the version of the standard supported by the compiler:
|
__STDC_HOSTED__ | 1 if the implementation is a hosted implementation (with all standard headers available)0 otherwise. |
The following macros are optionally defined, generally depending on whether a feature is available:
| macro | value |
|---|---|
__STDC__ | In C: if defined to 1, the implementation conforms to the C standard.In C++: Implementation defined. |
__STDC_VERSION__ | In C:
|
__STDC_MB_MIGHT_NEQ_WC__ | 1 if multibyte encoding might give a character a different value in character literals |
__STDC_ISO_10646__ | A value in the form yyyymmL, specifying the date of the Unicode standard followed by the encoding of wchar_t characters |
__STDCPP_STRICT_POINTER_SAFETY__ | 1 if the implementation has strict pointer safety (see get_pointer_safety) |
__STDCPP_THREADS__ | 1 if the program can have more than one thread |
Particular implementations may define additional constants.
For example:
This is the line number 7 of file /home/jay/stdmacronames.cpp.
Its compilation began Nov 1 2005 at 10:12:29.
The compiler gives a __cplusplus value of 1
23 - C++ INPUT / OUTPUT
C++ provides the following classes to perform output and input of characters to/from files:
- ofstream: Stream class to write on files
- ifstream: Stream class to read from files
- fstream: Stream class to both read and write from/to files .
These classes are derived directly or indirectly from the classes istream and ostream. We have already used objects whose types were these classes: cin is an object of class istream and cout is an object of class ostream. Therefore, we have already been using classes that are related to our file streams. And in fact, we can use our file streams the same way we are already used to use cin and cout, with the only difference that we have to associate these streams with physical files. Let's see an example:
[file example.txt]
Writing this to a file.
This code creates a file called example.txt and inserts a sentence into it in the same way we are used to do with cout, but using the file stream myfile instead.
But let's go step by step:
Open a file
The first operation generally performed on an object of one of these classes is to associate it to a real file. This procedure is known as to open a file. An open file is represented within a program by a stream (i.e., an object of one of these classes; in the previous example, this was myfile) and any input or output operation performed on this stream object will be applied to the physical file associated to it.
In order to open a file with a stream object we use its member function open:
open (filename, mode);
Where filename is a string representing the name of the file to be opened, and mode is an optional parameter with a combination of the following flags:
ios::in | Open for input operations. |
ios::out | Open for output operations. |
ios::binary | Open in binary mode. |
ios::ate | Set the initial position at the end of the file. If this flag is not set, the initial position is the beginning of the file. |
ios::app | All output operations are performed at the end of the file, appending the content to the current content of the file. |
ios::trunc | If the file is opened for output operations and it already existed, its previous content is deleted and replaced by the new one. |
All these flags can be combined using the bitwise operator OR (|). For example, if we want to open the file example.bin in binary mode to add data we could do it by the following call to member function open:
Each of the open member functions of classes ofstream, ifstream and fstream has a default mode that is used if the file is opened without a second argument:
| class | default mode parameter |
|---|---|
ofstream | ios::out |
ifstream | ios::in |
fstream | ios::in | ios::out |
For ifstream and ofstream classes, ios::in and ios::out are automatically and respectively assumed, even if a mode that does not include them is passed as second argument to the open member function (the flags are combined).
For fstream, the default value is only applied if the function is called without specifying any value for the mode parameter. If the function is called with any value in that parameter the default mode is overridden, not combined.
File streams opened in binary mode perform input and output operations independently of any format considerations. Non-binary files are known as text files, and some translations may occur due to formatting of some special characters (like newline and carriage return characters).
Since the first task that is performed on a file stream is generally to open a file, these three classes include a constructor that automatically calls the open member function and has the exact same parameters as this member. Therefore, we could also have declared the previous myfile object and conduct the same opening operation in our previous example by writing:
Combining object construction and stream opening in a single statement. Both forms to open a file are valid and equivalent.
To check if a file stream was successful opening a file, you can do it by calling to member is_open. This member function returns a bool value of true in the case that indeed the stream object is associated with an open file, or false otherwise:
Closing a file
When we are finished with our input and output operations on a file we shall close it so that the operating system is notified and its resources become available again. For that, we call the stream's member function close. This member function takes flushes the associated buffers and closes the file:
Once this member function is called, the stream object can be re-used to open another file, and the file is available again to be opened by other processes.
In case that an object is destroyed while still associated with an open file, the destructor automatically calls the member function close.
Text files
Text file streams are those where the ios::binary flag is not included in their opening mode. These files are designed to store text and thus all values that are input or output from/to them can suffer some formatting transformations, which do not necessarily correspond to their literal binary value.
Writing operations on text files are performed in the same way we operated with cout:
[file example.txt]
This is a line.
This is another line.
Reading from a file can also be performed in the same way that we did with cin:
This is a line.
This is another line.
This last example reads a text file and prints out its content on the screen. We have created a while loop that reads the file line by line, using getline. The value returned by getline is a reference to the stream object itself, which when evaluated as a boolean expression (as in this while-loop) is true if the stream is ready for more operations, and false if either the end of the file has been reached or if some other error occurred.
Checking state flags
The following member functions exist to check for specific states of a stream (all of them return a bool value):
bad()
Returns true if a reading or writing operation fails. For example, in the case that we try to write to a file that is not open for writing or if the device where we try to write has no space left.
fail()
Returns true in the same cases as bad(), but also in the case that a format error happens, like when an alphabetical character is extracted when we are trying to read an integer number.
eof()
Returns true if a file open for reading has reached the end.
good()
It is the most generic state flag: it returns false in the same cases in which calling any of the previous functions would return true. Note that good and bad are not exact opposites (good checks more state flags at once).
The member function clear() can be used to reset the state flags.
get and put stream positioning
All i/o streams objects keep internally -at least- one internal position:
ifstream, like istream, keeps an internal get position with the location of the element to be read in the next input operation.
ofstream, like ostream, keeps an internal put position with the location where the next element has to be written.
Finally, fstream, keeps both, the get and the put position, like iostream.
These internal stream positions point to the locations within the stream where the next reading or writing operation is performed. These positions can be observed and modified using the following member functions:
tellg() and tellp()
These two member functions with no parameters return a value of the member type streampos, which is a type representing the current get position (in the case of tellg) or the put position (in the case of tellp).
seekg() and seekp()
These functions allow to change the location of the get and put positions. Both functions are overloaded with two different prototypes. The first form is:
seekg ( position );
seekp ( position );
Using this prototype, the stream pointer is changed to the absolute position position (counting from the beginning of the file). The type for this parameter is streampos, which is the same type as returned by functions tellg and tellp.
The other form for these functions is:
seekg ( offset, direction );
seekp ( offset, direction );
Using this prototype, the get or put position is set to an offset value relative to some specific point determined by the parameter direction. offset is of type streamoff. And direction is of type seekdir, which is an enumerated type that determines the point from where offset is counted from, and that can take any of the following values:
ios::beg | offset counted from the beginning of the stream |
ios::cur | offset counted from the current position |
ios::end | offset counted from the end of the stream |
The following example uses the member functions we have just seen to obtain the size of a file:
size is: 40 bytes.
Notice the type we have used for variables begin and end:
streampos is a specific type used for buffer and file positioning and is the type returned by file.tellg(). Values of this type can safely be subtracted from other values of the same type, and can also be converted to an integer type large enough to contain the size of the file.
These stream positioning functions use two particular types: streampos and streamoff. These types are also defined as member types of the stream class:
| Type | Member type | Description |
|---|---|---|
streampos | ios::pos_type | Defined as fpos<mbstate_t>.It can be converted to/from streamoff and can be added or subtracted values of these types. |
streamoff | ios::off_type | It is an alias of one of the fundamental integral types (such as int or long long). |
Each of the member types above is an alias of its non-member equivalent (they are the exact same type). It does not matter which one is used. The member types are more generic, because they are the same on all stream objects (even on streams using exotic types of characters), but the non-member types are widely used in existing code for historical reasons.
Binary files
For binary files, reading and writing data with the extraction and insertion operators (<< and >>) and functions like getline is not efficient, since we do not need to format any data and data is likely not formatted in lines.
File streams include two member functions specifically designed to read and write binary data sequentially: write and read. The first one (write) is a member function of ostream (inherited by ofstream). And read is a member function of istream (inherited by ifstream). Objects of class fstream have both. Their prototypes are:
write ( memory_block, size );
read ( memory_block, size );
Where memory_block is of type char* (pointer to char), and represents the address of an array of bytes where the read data elements are stored or from where the data elements to be written are taken. The size parameter is an integer value that specifies the number of characters to be read or written from/to the memory block.
the entire file content is in memory
In this example, the entire file is read and stored in a memory block. Let's examine how this is done:
First, the file is open with the ios::ate flag, which means that the get pointer will be positioned at the end of the file. This way, when we call to member tellg(), we will directly obtain the size of the file.
Once we have obtained the size of the file, we request the allocation of a memory block large enough to hold the entire file:
Right after that, we proceed to set the get position at the beginning of the file (remember that we opened the file with this pointer at the end), then we read the entire file, and finally close it:
At this point we could operate with the data obtained from the file. But our program simply announces that the content of the file is in memory and then finishes.
Buffers and Synchronization
When we operate with file streams, these are associated to an internal buffer object of type streambuf. This buffer object may represent a memory block that acts as an intermediary between the stream and the physical file. For example, with an ofstream, each time the member function put (which writes a single character) is called, the character may be inserted in this intermediate buffer instead of being written directly to the physical file with which the stream is associated.
The operating system may also define other layers of buffering for reading and writing to files.
When the buffer is flushed, all the data contained in it is written to the physical medium (if it is an output stream). This process is called synchronization and takes place under any of the following circumstances:
- When the file is closed: before closing a file, all buffers that have not yet been flushed are synchronized and all pending data is written or read to the physical medium.
- When the buffer is full: Buffers have a certain size. When the buffer is full it is automatically synchronized.
- Explicitly, with manipulators: When certain manipulators are used on streams, an explicit synchronization takes place. These manipulators are: flush and endl.
- Explicitly, with member function sync(): Calling the stream's member function sync() causes an immediate synchronization. This function returns an int value equal to -1 if the stream has no associated buffer or in case of failure. Otherwise (if the stream buffer was successfully synchronized) it returns 0.
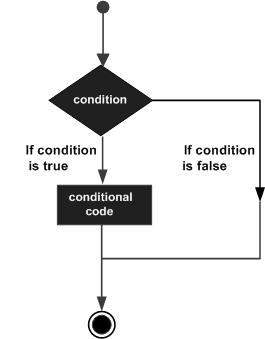
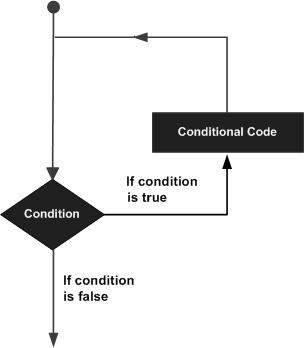

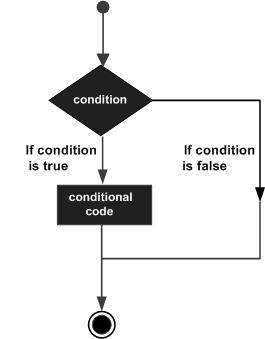
.jpg)
.jpg)